31회 ADP 실기 후기

17회 필기를 한 번에 합격하고 나서 취업과 네이버부스트캠프 등을 하느라 제대로 공부하지 못한 상태로 실기에 도전하게 되었고, 2년이라는 유효기간 내에 결국 합격하지 못했습니다. 그래서 다시 작년에 28회 필기시험을 또 합격한 다음, 이번에는 꼭 따보리라 다짐했습니다만 역시나 31회 실기 시험에서 54.3점으로 불합격하게 되었습니다. 2024년부터는 4회 시험에서 2회 시험으로 줄게 되면서 이제 2번의 기회만 남은 상황이 되었습니다. 지난 시험을 다시 회고를 해보면서 문제점은 어떤 것들이 있었는지, 어떤 것들을 보완해야 하는지에 대해 먼저 적어보겠습니다.
첫 번째, 오픈 북이지만 책을 볼 시간이 없습니다. 나만의 정리 자료가 필요합니다. 대학교에서 오픈 북 시험을 한 경험이 있다면, 다들 느끼셨을 겁니다. 오픈 북인 이유가 있다는 것을.. 이 시험도 기본적인 체득된 전처리 능력 등이 수반되어야 주어진 시간 안에 문제를 풀 수 있습니다. 나만의 정리 노트를 만들고, 금방 금방 원하는 개념을 확인하고 바로 풀어낼 수 있도록 자료를 활용해야 합니다.
두 번째, 모의 시험을 통해서 시간 분배하는 것에 대한 연습이 필요합니다. 처음에는 4시간이 엄청 많아 보이는데, 문제를 풀다 보면, 20~30분씩 훅훅 지나갑니다. 또한, 답안지 작성하는 것도 생각보다 시간을 많이 잡아먹습니다.
세 번째, 통계분석 준비보다는 머신러닝 비중 증가, 최근 ADP 실기 시험에서 배점의 형태가 통계분석 40점, 머신러닝 60점으로 변화하면서 머신러닝의 비중이 커지고 있습니다. 최근 통계분석 문제에서는 분석방법을 알면 풀고, 모르면 못 푸는 형태로 나오고 있고, 머신러닝의 경우에는 데이터셋이 주어지고 가지문제가 많이 나오다 보니, 빠르게 풀 수 있는 능력이 중요하다고 느껴졌습니다.
2월이 시작된 지금부터 4월 시험을 위해 저만의 노트를 만들면서 헷갈리는 내용이나 익숙하지 않았던 내용들을 정리해보려고 합니다. 특히, 이번 31회 시험에서 가장 시간을 많이 썼었던 부분이 날짜 데이터 처리하는 부분이었습니다. 당연히 많이 다뤄봤으니, 금방 풀 수 있었을 거라고 생각했는데, 생각보다 원하는 대로 값이 안나왔습니다. 실제 문제에서는 생년월일이 주어지고, 기준일까지의 만 나이를 계산하는 문제가 나왔습니다. 어찌어찌 시간을 써서 문제는 풀어봤지만, 조금 더 명확한 개념을 가지고 문제를 풀 수 있도록 Datetime에 대한 내용들을 정리해보겠습니다.
날짜 데이터에 대하여
기본적으로 ADP에서는 테이블형태의 데이터(정형 데이터)가 주어집니다. 우선 데이터를 받았을 때, 각 데이터의 type을 확인하기 위해 info 명령어로 체크하게 됩니다. 기본적으로 string 형태, datetime형태, timestamp형태, timedelta형태 등이 존재합니다.

우선 크게 특정 시점을 나타내는 TimeStamp와 시점 사이의 일정한 기간을 나타내는 Period가 있습니다. 2023-12-15가 Period라고 한다면, 해당 일자 00시부터 24시까지를 말한다고 이해하시면 됩니다.
날짜 데이터는 주로 다른 특정 Feature를 추출하기 위해서 사용합니다. 예를 들면, 어플리케이션에서 퍼널과 퍼널 사이의 시간을 구하고자 할 때, 각 퍼널에 유입된 시점을 TimeStamp로 찍어두고 두 시점 사이의 Timedelta를 구하여 분석할 수 있습니다. 하지만, string 형태의 데이터는 더하기나 빼기 연산등을 할 수 없기에 datetime의 형태로 변환해 줘야 사용할 수 있습니다.
데이터 변환하기
우선 테이블 데이터의 경우에는 pandas의 dataframe으로 불러오는 경우가 많습니다. 가장 처음에 데이터를 불러오면, 데이터 타입이 어떻게 되는지 확인해야 합니다. dtype에 따라 적용할 수 있는 것들이 다르다 보니, 각 dtype 별로 내용을 정리해 봅시다.
string 형태로 들어간 데이터
데이터가 string 형태(object)로 되어 있는 경우에는 더하기나 빼기 연산을 통해 Timedelta를 구할 수 없습니다. 그렇기 때문에 string 형태에서 datetime 형태로 변환이 필요합니다.
변환하는 방법은 크게 2가지 정도 활용할 수 있습니다. 첫 번째는 pandas에서 제공하는 pd.to_datetime을 사용하는 방법, 두 번째는 datetime에서 strptime을 활용하는 방법이 있습니다.
위와 같은 임의의 테이블이 있는 경우, info를 통해 date_of_birth의 dtype을 확인해 보니, object라고 나오는 것을 확인했습니다.

그렇다면 string 형태이므로, timedelta를 구하거나, 년/월/일 등을 추출하기 위해서는 위에서 언급한 2가지 방법을 사용할 수 있습니다. 위에서 언급한 방법을 활용해서 새로운 열을 만들어보도록 하겠습니다. 이때, strptime을 사용할 때에는 pd.Series에 바로 적용하기 어려우므로, apply 함수를 활용해야 합니다.
import pandas as pd
from datetime import datetime
df = pd.read_csv('./dataset.csv', encoding='euc-kr')
# pandas 활용
df['to_datetime_date_of_birth'] = pd.to_datetime(df['date_of_birth'])
# strptime 함수 활용
df['strptime_date_of_birth'] = df['date_of_birth'].apply(lambda x : datetime.strptime(x, '%Y-%m-%d'))위의 코드를 실행하면 아래처럼 datetime의 두 열이 생긴 것을 확인할 수 있습니다.
그러면, 위에 데이터에서 2000년생 이상인 사람들만 필터 해서 확인하고 싶을 때에는 어떻게 해야 할까요? string 형태에서도 부등호를 통한 데이터 필터링이 가능합니다. 이때, 기준이 되는 값도 string이어야 가능합니다. 만약, 2000-01-01이 TimeStamp로 되어 있다면, TypeError가 발생하게 됩니다.

Datetime 형태로 들어간 데이터
datetime으로 된 데이터의 경우에는 앞에서 활용했던 부등호를 포함하여, 더하기, 빼기를 통해 Timedelta를 구할 수 있습니다. 또한 날짜 데이터에서 year, month, day 등을 손쉽게 추출할 수 있습니다. 아까 했던 것처럼 2000년생 이상인 사람들만 필터 해서 확인할 때에는 기준값이 string이어도, timestamp여도 모두 동작합니다.
그러면 오늘을 기준으로 각 사람들의 나이를 구해보면 어떻게 될까요? 오늘 날짜의 TimeStamp를 구해준 다음에 now에서 각 생일의 값을 빼주면 되겠죠.
Timedelta의 경우에는 1일 이하의 기준으로 생성되기 때문에 정확하게 만 나이 구하려면, 태어난 월과 일을 비교해야 하지만, 1년이 365일이라고 가정해서 위에 값을 저장하여 365로 나눈 몫을 구해서 구하면 아래와 같이 구할 수 있습니다.
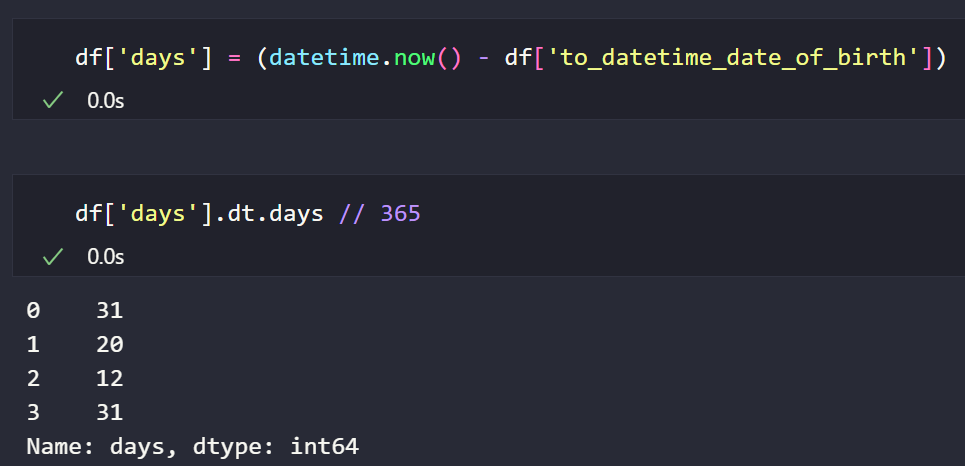
위에서 처럼 dt 속성을 활용하여 days를 구할 수 있는데, 위에서 얻은 값은 TimedeltaProperties이라서 days, hours, minutes, seconds, milliseconds, microseconds 등을 사용할 수 있습니다.
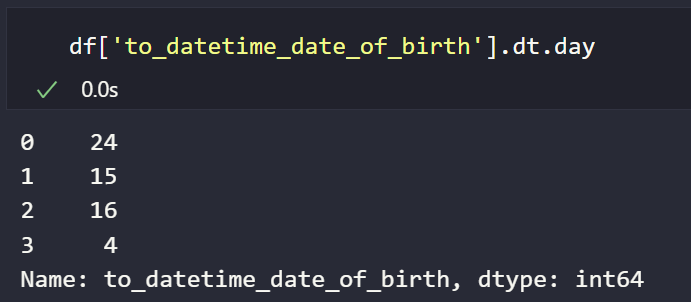
datetime에서도 동일하게 dt 속성을 활용할 수 있는데, TimedeltaProperties와 다르게 year, month, day, hour, minute, second, microsecond를 추출할 수 있습니다.
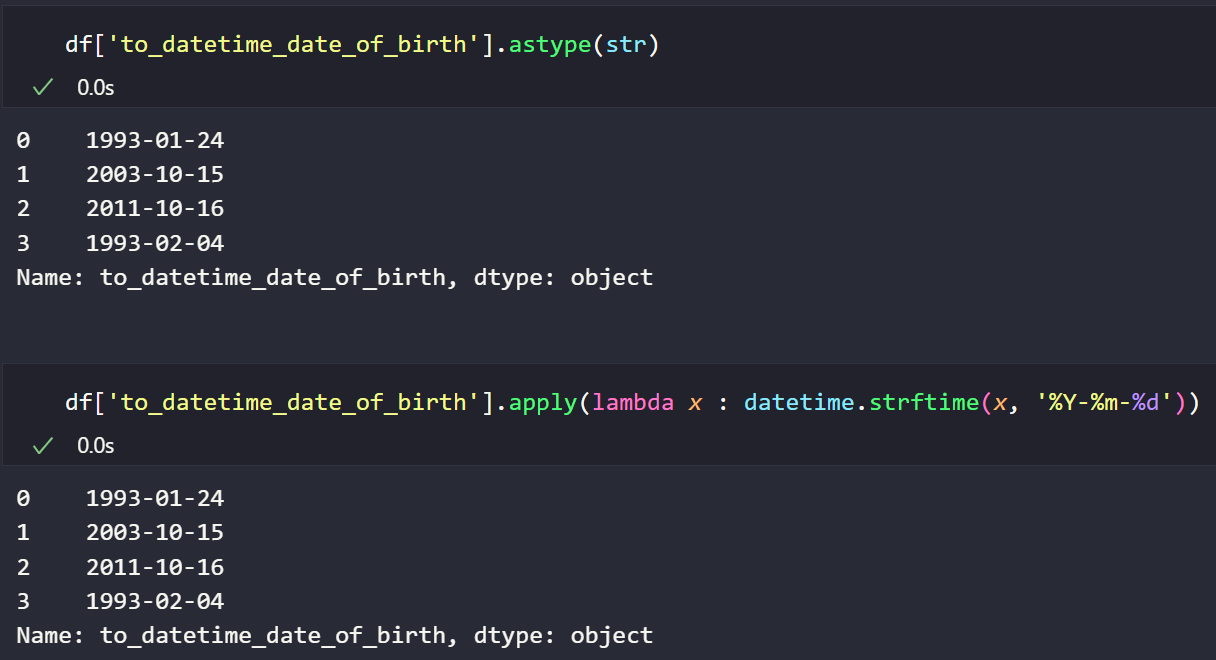
마지막으로 datetime 형태의 데이터를 다시 string 형태를 변경하기 위해서는 astype(str)과 datetime의 strftime 함수를 사용할 수 있습니다. strftime은 위에서 사용한 strptime과 동일하게 Series에는 적용이 안되므로 apply 등을 활용하여 적용해줘야 합니다.
3줄 요약
- 날짜 데이터 형태에는 TimeStamp(특정 시점)와 Period(기간)가 존재합니다.
- 데이터셋에서 날짜 열의 데이터 타입이 string, datetime, timedelta인지에 따라 적용할 수 있는 함수가 다릅니다.
- string형태의 날짜 데이터를 그대로 사용하기보다는 datetime 형태로 변환해 줘야 더 많은 연산을 활용할 수 있습니다.