해당 포스팅은 네이버 부스트캠프 AI Tech 학습 정리 자료임을 알려드립니다.
1. 강의 정리
오태현 교수님 - Multi-modal learning: Captioning and Speaking
1) Overview of multi-modal learning
컴퓨터 비전에서는 주로 시각자료를 활용해서 많은 Task를 해결해왔습니다. 이렇게 한가지의 감각을 활용하는 것을 Unimodal이라고 하고, 이것 말고 다양한 청각, Text 등 다양한 감각을 동시에 사용하는 방법이 Multi-modal입니다. 이번 강의에서는 vision을 중심으로 활용한 multi-modal에 대해서 주로 다루게 됩니다.
Multi-modal learning을 할 때, 가장 어려운 점은 각 데이터가 다른 형태라는 것입니다. 예를 들어, audio의 경우 1-D signal의 wave form형태를 가지고, 이미지의 경우 2-D array, 3-D array 형태를 가집니다. Text data는 표현하기가 굉장히 어려워서 단어 하나를 임베딩한 벡터로 변환해서 주로 활용합니다.
또한 두번째로는 한 텍스트에 대해 1개의 이미지가 생성되는 것이 아니라, 다양한 이미지가 나올 수 있다는 것입니다. 즉, 다른 feature spaces 간의 불균형이 존재합니다.
세번째로는 Multi-modal로 데이터를 학습시킨다고 무조건 좋은 것은 아닙니다. 모델을 학습하는 방법때문에 오히려 방해가 될 때도 존재합니다. 한 쪽의 modal에 편향을 가지고 다른 한 쪽은 아예 사용하지 않을 수 있는 문제가 있습니다. 그렇지만 이렇게 multi-modal을 통해서 우리가 이전에는 해결하지 못하는 문제들을 해결할 수도 있습니다.

위의 그림처럼 다양한 방법의 Multi-modal learning이 존재합니다. Matching은 각각의 데이터를 동일한 데이터의 형태로 변환시켜서 매칭시키는 방법입니다. Translating은 한개의 데이터 형태를 또 다른 데이터의 형태로 변환시켜주는 방법입니다. Referencing은 하나의 데이터의 형태를 output으로 얻고 싶을 때, 다른 형태의 modal을 참조하는 형태입니다.
2) Multi-modal tasks - Visual data & Text

Matching 방법을 활용한 대표적인 것은 Image tagging이 있습니다. image가 주어지면 주어진 이미지에서 tag를 생성하거나 태그가 주어지면 image를 찾아내는 Task입니다.

위의 그림처럼 Text data와 Image data를 각각 Feature vector형태로 만들어서 동일한 차원의 벡터형태로 만들어서 Joint embedding을 통해서 학습합니다.

위의 그림처럼 joint embedding 부분에서는 매칭되는 쌍의 경우에는 가까운 곳에 위치할 수 있도록 거리를 가깝게 하고, 매칭이 안되는 경우에는 거리를 멀게 하는 방식으로 학습합니다.

위의 그림처럼 강아지 그림을 주고, -dog+cat을 해주니까 고양이 사진이 출력되는 것을 확인할 수 있습니다.

위의 그림처럼 이미지와 레시피를 연결시킨 재미있는 연구들이 진행되었습니다.

Recipe는 보통 순서가 있는 데이터이기 때문에 이것을 처리하기 위해서 RNN 계열의 네트워크를 활용했습니다. recipe는 ingredient 부분과 instruction 부분을 concatenate 해서 벡터를 얻습니다. 얻어진 벡터를 fully connected layer를 통해서 fixed dimension vector를 얻어냅니다. 이미지를 통해 얻은 벡터와 recipe 벡터의 코사인 유사도를 구합니다. 유사도는 연관이 되어 있을 경우 값이 커지게 됩니다. cosine similarity loss로 해결안되는 경우에는 semantic regularization loss를 활용해서 가이드를 해줍니다.

Translating을 활용한 방법 중 대표적으로는 image captioning(image to sentence)이 있습니다. image를 이해하기 위해서 CNN을, 순서가 있는 문장 정보를 출력하기 위해서는 RNN 계열의 네트워크가 필요합니다. 그래서 2가지 네트워크를 합친 것이 show and tell이라는 방법입니다.
show and tell은 Encoder에는 ImageNet으로 미리 학습한 CNN model을 사용하고, CNN을 통해서 얻은 fixed dimension vector를 RNN의 초기 state로 입력해줍니다. RNN에서는 start 토큰을 넣어주고 얻은 결과를 다음 input으로 넣어주는 방식으로 진행됩니다. 하지만 show and tell은 이미지 전체를 하나의 벡터에 표현하기 때문에 국지적인 요소에 집중하기 어렵다는 특징이 존재합니다. 그래서 이것을 보완하는 방법인 show, attend, and tell이 등장했습니다.

show and tell에서는 CNN을 통해서 fixed dimension vector를 RNN으로 넘겨줬지만, 이 방법에서는 fixed dimension vector말고 공간정보를 유지한 Feature Map을 넘겨주는 차이가 있습니다.

이미지가 CNN을 통해서 Feature map형태를 얻고, 그 얻어진 Feature map을 RNN의 state로 입력시켜서 어떤 부분을 봐야하는 지를 히트맵으로 만들게 됩니다. 그렇게 만들어진 히트맵과 Feature map의 weighted sum을 통해서 z를 구하게 됩니다.

Inference할 때, 공간 정보를 가진 feature map이 LSTM의 condition인 $h_{0}$으로 들어가서 어떤 부분을 볼 지를 표현한 $s_{1}$을 feature map과 weighted sum으로 $z_{1}$을 얻고 start token인 $y_{1}$을 input을 넣어서 A라는 $d_{1}$과 $S_{2}$를 얻습니다. 반복적인 과정으로 우측화면의 단어들을 순서대로 얻을 수 있습니다.

Text에서 image로 바꾸는 경우에는 unique 영상을 가지지 않습니다. 그래서 Generative model을 활용하는 것이 좋습니다.

위의 그림처럼 Generator Network와 Discriminator Network로 나눌 수 있습니다. Generator Network에서 Gaussian Random code는 똑같은 input이 들어갔을 때, 항상 똑같은 결과가 나오는 것을 방지하는 역할을 합니다. 그렇게 decoder를 통해 얻어진 이미지는 Discriminator Network의 Encoder를 통해 얻어진 것과 Text를 Fixed dimension vector로 변환한 것과 비교해서 같은 지 확인합니다.
Referencing의 대표적인 Task는 Visual question answering이 있습니다.
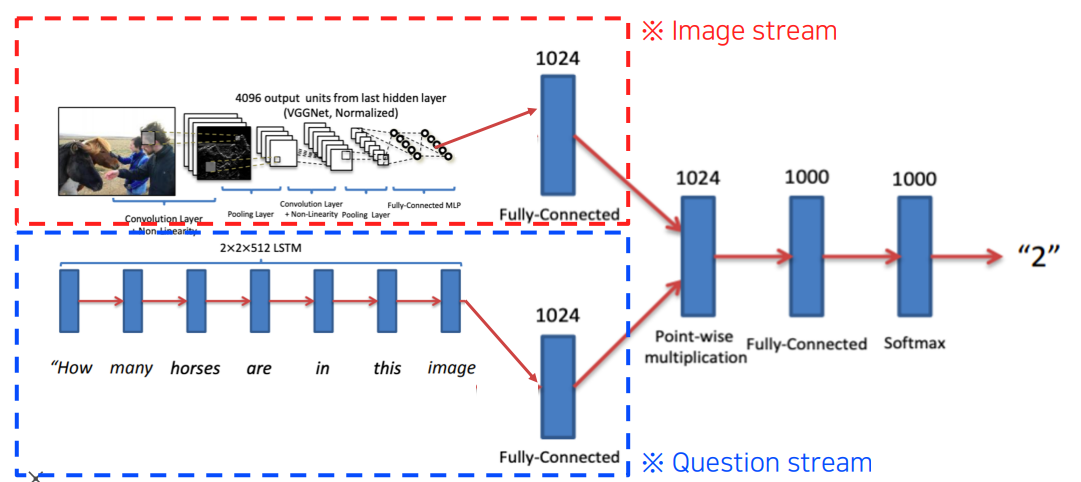
Visual question answering은 image stream과 Question stream으로 얻어진 fixed dimensional vector로 Point-wise multiplication을 해서 답을 얻어낼 수 있습니다.
3) Multi-modal tasks - Visual data & Audio

Sound는 기본적으로 Wave form 형태를 가집니다. 이것을 활용하기 위해서는 spectogram이나 MFCC 등의 변환과정으로 새로운 형태의 데이터를 얻습니다.
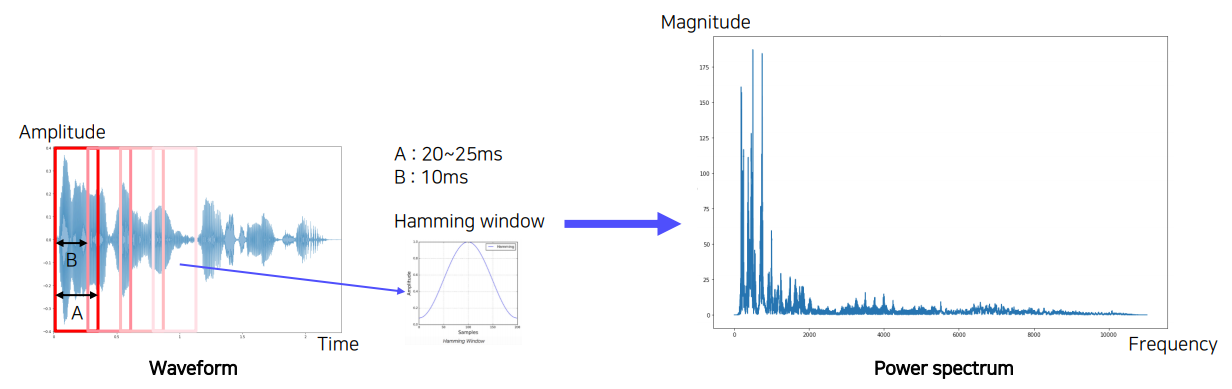
가장 대표적인 Sound representation 방법 중 Short-time Fourier transform은 일반적인 Fourier transform을 사용했을 때 시간에 대한 정보손실을 줄여주는 방법입니다. 위의 그림처럼 Waveform을 일정간격으로 window를 옮겨가면서 Hamming window을 elementwise해서 가운데 있는 것은 강조하고, 끝에 있는 것들은 덜 강조합니다.

그렇게 구간별로 얻어진 Power spectrum들을 시간 축으로 stack하면 spectrogram을 얻을 수 있습니다. 이외에도 Melspectrogram, MFCC가 있습니다.
Sound data를 활용한 Matching(joint embedding) 방법의 주요 Task는 Scene recognition이 있습니다. Scene recognition은 소리로 장면을 추측하는 방법입니다. Scene recognition에서 활용된 SoundNet에 대해 알아봅시다.

RGB Frame 쪽은 Teacher에 해당하기에 학습하지 않고, Raw Waveform이 들어가는 CNN구조를 학습하는 방식을 사용합니다. Video에서 RGB Frame을 각각의 CNN을 통해 Object Distribution, Scene Distribution을 구합니다. Raw Waveform은 CNN 구조를 지나서 2개의 Head를 얻게 됩니다. 그 중 하나는 Scene recognition을 학습하고, 나머지 하나는 object recognition을 학습합니다. 각각의 recognition은 Video로부터 얻은 object distribution과 Scene Distribution과의 KL-divergence를 최소화하는 방향으로 학습이 진행됩니다. 이러한 학습 방법을 Teacher-student라고 하기도 하고, transfer learning이라고 부르기도 합니다. 비슷하게 장면인식말고 다른 Task에서 활용하고 싶을 때에는 pool5에서 classifier를 학습시켜서 target task에 적용할 수 있습니다. conv8을 적용하지 않는 이유는 장면 인식에 specific해졌기 때문에 좀 더 일반화된 pool5를 활용합니다.

Translating을 활용한 모델에는 음성을 듣고, 사람 얼굴을 추측하는 네트워크인 Speech2Face가 존재합니다. 이 모델은 Module network로 각자 담당하고 있는 미리 학습된 네트워크를 조합하는 방식을 사용합니다. 또한 video의 경우, annotation이 추가로 필요하지 않다는 장점이 있습니다. 음성과 영상이 이미 paired되어 있기 때문에 일종의 self-supervised learning입니다. 이외에도 이미지에서 음성을 만드는 Image-to-speech sythesis가 존재합니다.

마지막으로 Referencing을 활용한 대표적인 Task에는 Sound source localization이 존재합니다. 소리와 이미지를 input으로 넣어서 소리가 이미지의 어떤 부분에서 나는지를 localization하는 Task입니다. 동시에 음성이 섞여있는 비디오에서 각각의 음성을 추출하는 방법인 cocktail party라는 모델도 존재합니다.
오태현 교수님 - 3D Understanding
1) Seeing the world in 3D perspective
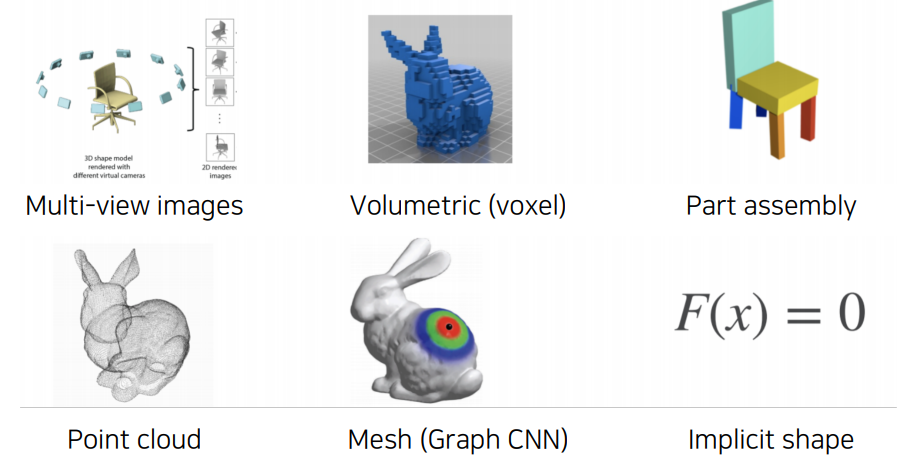
컴퓨터비전 분야의 꽃이라고 할 수 있는 3D는 왜 중요할까요? 그것은 우리 현실 세계와 밀접하게 관련이 있기 때문입니다. 3D 분야에는 대표적으로 AR/VR, 3D 프린팅 기술도 있습니다. 이외에도 의학 분야나 화학에서도 많이 사용됩니다. 일반적인 사진들은 3D 장면을 projection으로 얻은 2D 이미지입니다. 이러한 2D 이미지들로 3D 점을 얻어내는 방법으로 Triangulation이 있습니다. 자세한 내용은 Multiple View in Geometry in computervision을 참고하시면 좋을 것 같습니다. 3D data는 위의 보시는 그림처럼 다양하게 표현이 가능합니다.
3D 이미지로 이루어진 데이터셋에는 직접 디자인한 ShapeNet, 객체들을 직접 표현한 PartNet, 이외에도 SceneNet, ScanNet, Outdoor 3D scene datasets(KITTI, Semantic KITTI, Waymo Open Dataset) 등이 존재합니다.
2) 3D tasks

3D data도 기존 2D 이미지들과 동일하게 다양한 task가 존재합니다. 3D 이미지의 객체로부터 어떤 객체인지 인식하는 3D object recognition, 자율주행에서 사용되는 3D object detection, 3D semantic segmentation, 일반 2D image로 Mesh를 생성하는 Conditional 3D generation이 존재합니다.