해당 내용은 Datacamp의 Data engineering track을 정리했습니다.
Introduction to data engineering의 chapter 4에 대한 내용입니다.
해당 포스팅에는 아래의 내용을 포함하고 있습니다.
- DataCamp에서 rating 시스템을 활용한 강의 추천시스템에 배운 것들을 적용하기
1. Course ratings

DataCamp에서는 강의를 마치고 나면 강의에 대한 평가를 진행하게 됩니다. 이렇게 유저가 평가한 강의에 대한 정보를 기반으로 다음에 유저가 들을만한 강의를 추천해주는 시스템을 만들 수 있습니다. 시스템을 구현하기 위해서는 먼저, 평가 데이터를 가져오는 작업을 진행해야 하고, 그 다음으로 가장 추천하는 강의들을 찾는 작업을 진행합니다. 매일 동일하게 측정해서 새로운 결과로 추천해줍니다. 추천된 강의를 유저의 대시보드로 띄워줍니다.
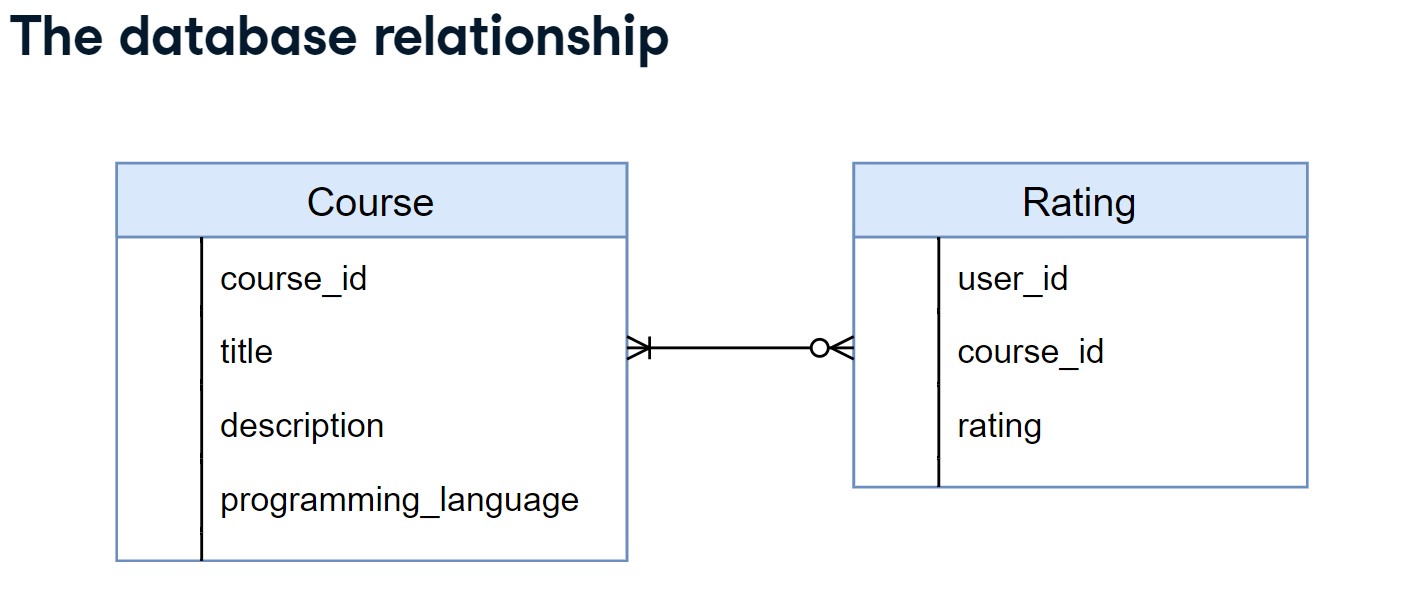
이번 강의에서는 위의 테이블 2개를 적용해볼 것입니다. 위의 그림은 2개 테이블의 관계를 표현한 것으로 보시면 됩니다.
# Transformation function
def transform_avg_rating(rating_data):
# Group by course_id and extract average rating per course
avg_rating = rating_data.groupby('course_id').rating.mean()
# Return sorted average ratings per course
sort_rating = avg_rating.sort_values(ascending=False).reset_index()
return sort_rating
# Extract the rating data into a DataFrame
rating_data = extract_rating_data(db_engine)
# Use transform_avg_rating on the extracted data and print results
avg_rating_data = transform_avg_rating(rating_data)
print(avg_rating_data)2. From ratings to recommendations
추천시스템에서는 행렬 분해와 같은 테크닉이 필요합니다. 해당 내용에 관해서 자세히 알고 싶다면, DataCamp의 강의 "Building Recommendation Engines with PySpark"를 들어보시면 좋습니다. 이 강의에서는 추천시스템에 대한 기술적인 내용은 다루지 않습니다. 추천을 하기 위해서 다음의 조건을 만족하려고 합니다. 첫 번째, 가장 점수가 높은 언어를 추천합니다. 두 번째, 이미 측정된 강의는 추천하지 않습니다. 세 번째, 1번과 2번을 조건을 만족하는 강의들 중에서 가장 높은 평점을 가지는 3개의 강의를 추천합니다.
# Filter out corrupt data
course_data = extract_course_data(db_engines)
# Print out the number of missing values per column
print(course_data.isnull().sum())
# The transformation should fill in the missing values
def transform_fill_programming_language(course_data):
imputed = course_data.fillna({"programming_language": "R"})
return imputed
transformed = transform_fill_programming_language(course_data)
# Print out the number of missing values per column of transformed
print(transformed.isnull().sum())위의 코드는 course_data를 불러와서 결측치를 채워주는 작업을 진행합니다.
# Using the recommender transformation
# Complete the transformation function
def transform_recommendations(avg_course_ratings, courses_to_recommend):
# Merge both DataFrames
merged = courses_to_recommend.merge(avg_course_ratings)
# Sort values by rating and group by user_id
grouped = merged.sort_values("rating", ascending=False).groupby("user_id")
# Produce the top 3 values and sort by user_id
recommendations = grouped.head(3).sort_values("user_id").reset_index()
final_recommendations = recommendations[["user_id", "course_id","rating"]]
# Return final recommendations
return final_recommendations
# Use the function with the predefined DataFrame objects
recommendations = transform_recommendations(avg_course_ratings, courses_to_recommend)평균값이 구해진, avg_course_ratings와 course_to_recommend 2개를 merge하고 user_id별로 묶은 뒤 평점 기준으로 높은 것부터 정렬해서 가장 높은 3개를 recommendations로 담아서 해당 강의에 대한 정보를 반환해주는 Transformation 작업입니다.
3. Scheduling daily jobs
마지막으로 앞에서 했던 Transformation 결과를 PostgresSQL로 Load하고 매일 업데이트하도록 스케줄링하려고 합니다.
def etl(db_engines):
# Extract the data
courses = extract_course_data(db_engines)
rating = extract_rating_data(db_engines)
# Clean up courses data
courses = transform_fill_programming_language(courses)
# Get the average course ratings
avg_course_rating = transform_avg_rating(rating)
# Get eligible user and course id pairs
courses_to_recommend = transform_courses_to_recommend(rating, courses)
# Calculate the recommendations
recommendations = transform_recommendations(avg_course_rating, courses_to_recommend)
# Load the recommendatuions into the database
load_to_dwh(recommendations, db_engine))
connection_uri = "postgresql://repl:password@localhost:5432/dwh"
db_engine = sqlalchemy.create_engine(connection_uri)
def load_to_dwh(recommendations):
recommendations.to_sql("recommendations", db_engine, if_exists="replace")
# Define the DAG so it runs on a daily basis
dag = DAG(dag_id="recommendations",
schedule_interval="0 0 * * *")
# Make sure `etl()` is called in the operator. Pass the correct kwargs.
task_recommendations = PythonOperator(
task_id="recommendations_task",
python_callable=etl,
op_kwargs={"db_engines": db_engines},
)