해당 내용은 Datacamp의 Data engineering track을 정리했습니다.
Streamlined Data Ingestion with pandas의 chapter 4에 대한 내용입니다.
해당 포스팅에는 아래의 내용을 포함하고 있습니다.
- JSON 파일 소개 및 Pandas에서 불러오기
- API 소개 및 requests로 데이터 가져오기
- 리스트로 묶인 JSON파일 처리하기
- 여러 개의 데이터를 합치기
1. Introduction to JSON
JSON은 Javascript Object Notation의 약자로 주로 웹 데이터 공식 포맷입니다. Tabular 데이터와 다른 점은 모든 속성 값을 반드시 가질 필요가 없습니다. 또한 1:1 관계가 아니라, 1:N 관계로 data mapping이 가능한 형태입니다. 추가적으로 파이썬에서 dictionary 형태와 매우 유사합니다.
JSON 파일을 pandas에서 읽을 때에는 read_json함수를 활용할 수 있습니다. JSON은 row-oriented형식과 column-oriented 형식이 둘 다 가능합니다. oriented라는 인수로 JSON 형식을 알려줄 수 있습니다. 자세한 내용은 pandas 공식 홈페이지에서 확인해보실 수 있습니다.
2. Introduction to APIs
API는 Application Programming Interfaces로 다른 프로그램과 연결하는 방법입니다. 일반적으로 API를 통해 받을 수 있는 데이터양은 제한적일 때가 많이 있습니다. 웹사이트로부터 데이터를 받기 위해서는 Requests라는 라이브러리를 활용해야 합니다. requests.get("URL 주소")를 통해서 URL의 데이터를 얻어올 수 있습니다. 추가 인자로는 params와 headers가 존재합니다. params는 원하는 parameter의 특정 값에 대한 정보가 궁금할 때, 조건으로 줄 수 있고, dictionary 형태로 입력합니다. headers는 API에 권한을 부여할 때 필요한 token값을 입력하는 부분입니다. requests.get으로 얻어진 정보는 response라는 객체로 얻어지며, response.json을 통해 json형태의 데이터를 얻을 수 있습니다. response.json은 read_json과 다르게 dictionary 형태를 가집니다.
import requests
import pandas as pd
api_url = "https://api.yelp.com/v3/businesses/search"
params = {"term": "bookstore", "location": "San Francisco"}
headers = {"Authorization": "Bearer {}".format(api_key)}
response = requests.get(api_url, params=params, headers=headers)
data = response.json()
bookstores = pd.DataFrame(data["businesses"])
3. Working with nested JSONs
JSON 파일은 1개의 key에 여러 개의 값이 dictionary 형태로 들어갈 수도 있고, list 형태로 포함될 수 있습니다. 이런 경우에는 pandas.io.json을 활용해서 JSON 파일을 불러오는 것이 좋습니다. json_normalize는 flattening 하는 작업이 필요합니다. flattening 작업은 nested 된 리스트를 풀어서 하나의 칼럼으로 표현될 수 있습니다.
import pandas as pd
import requests
from pandas.io.json import json_normalize
api_url = "https://api.yelp.com/v3/businesses/search"
headers = {"Authorization": "Bearer {}".format(api_key)}
params = {"term": "bookstore", "location": "San Francisco"}
response = requests.get(api_url, headers=headers, params=params)
data = response.json()
bookstores = json_normalize(data["businesses"], sep="_")
json_normalize 사용할 때에는 record_path, meta, meta_prefix argument를 통해서 자세한 정보를 입력해줄 수 있습니다.
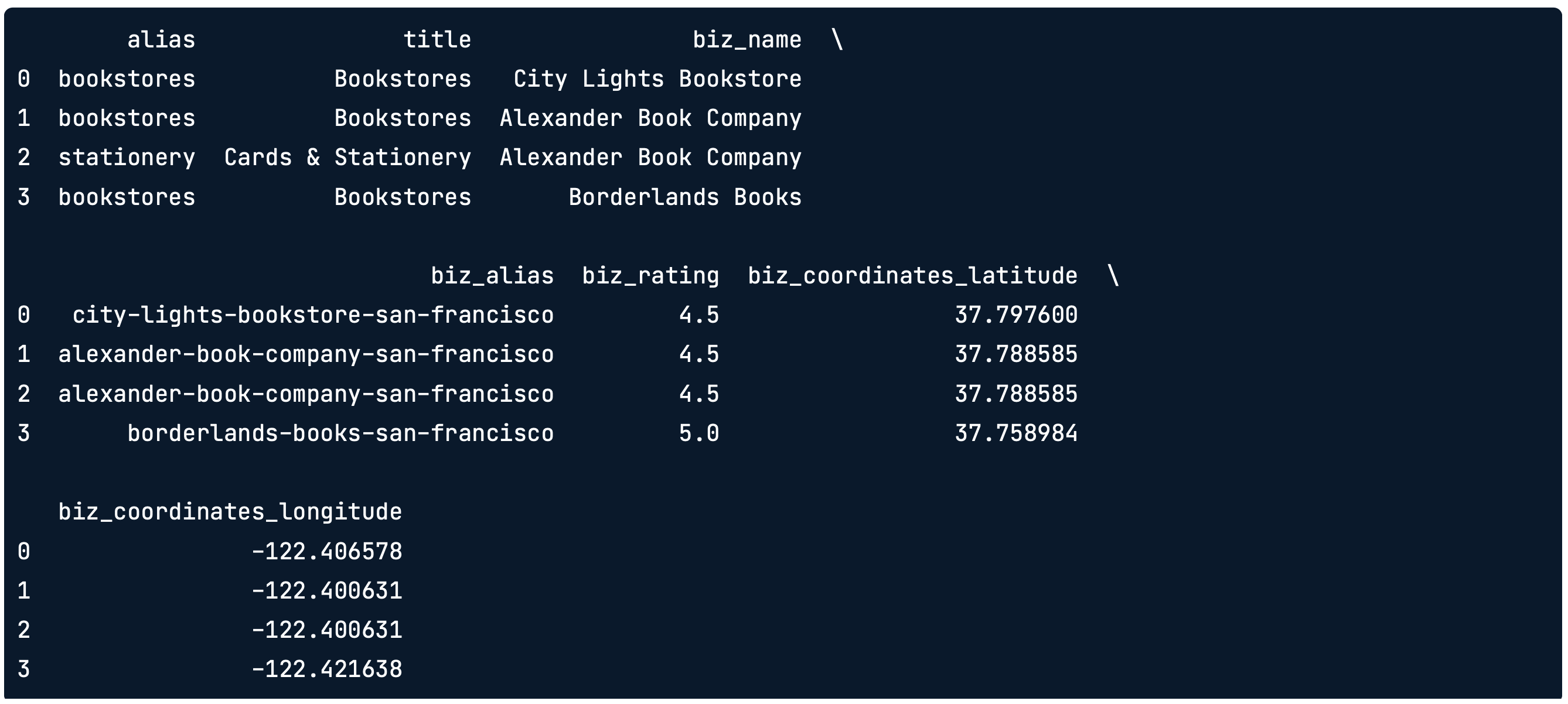
df = json_normalize(data["businesses"], sep="_", record_path="categories",
meta=["name", "alias", "rating", ["coordinates", "latitude"], ["coordinates", "longitude"]],
meta_prefix="biz_")위의 코드를 실행하면 아래와 같은 형태의 데이터를 얻을 수 있습니다. 각 meta column에 대해서 biz_라는 prefix가 붙으며, 리스트 형태로 주어진 경우에는 ["A", "B"]라고 가정했을 때, biz_A_B라는 칼럼으로 생성되는 것을 확인할 수 있습니다.
4. Combining multiple datasets
여러 개의 데이터를 합치는 방법은 append와 merge가 존재합니다. append는 dataframe끼리 합치는 경우에 활용합니다. ignore_index = True로 설정해야 row를 새로운 인덱스로 설정합니다.
params = {"term": "bookstore", "location": "San Francisco"}
first_results = requests.get(api_url, headers=headers, params=params).json()
first_20_bookstores = json_normalize(first_results["businesses"], sep="_")
params["offset"] = 20 # 다음 가져올 시작점
next_results = requests.get(api_url, headers=headers, params=params).json()
next_20_bookstores = json_normalize(next_results["businesses"], spe="_")
bookstores = first_20_bookstores.append(next_20_bookstores, ignore_index=True)처음 20개와 두번째 20개의 데이터를 append 하게 되면 40개짜리의 데이터가 만들어지게 됩니다.
두 번째 방법은 Merge를 사용하는 것입니다. Merge는 기본적으로 SQL에서 join 연산을 떠올리시면 됩니다. foreign key 설정을 위해 left_on과 right_on이라는 argument에 테이블 칼럼을 넣어줘야 합니다. 칼럼 2개의 데이터 타입은 항상 같아야 Merge가 가능합니다.
merged = call_counts.merge(weather, left_on="created_date", right_on="date")left_on은 call_counts의 칼럼이고, right_on은 weather의 칼럼을 넣어주면 됩니다.