해당 내용은 Datacamp의 Data engineering track을 정리했습니다.
Data Processing in Shell의 chapter 2에 대한 내용입니다.
해당 포스팅에는 아래의 내용을 포함하고 있습니다.
- csvkit(in2csv, csvlook, csvstat, csvcut, csvgrep, csvstack)
1. Getting started with csvkit
csvkit은 command-line에서 데이터 처리를 위한 툴입니다. Wireservice가 Python을 사용해서 개발한 csvkit은 다양한 기능(데이터 변환, 처리 및 정리 기능)을 제공합니다. csvkit은 python 패키지이기 때문에 pip를 통해 설치할 수 있습니다. 이미 설치된 경우 최신 버전으로 업그레이드를 위해서 --upgrade로 설치할 수 있습니다.
pip install (--upgrade) csvkitin2csv는 텍스트나 Excel과 같은 테이블 형식 데이터 파일을 csv로 변환합니다.
# Syntax
in2csv SpotifyData.xlsx > SpotifyData.csv
# 첫번째 sheet를 출력하고 저장하지 않음
in2csv SpotifyData.xlsx만약, 원하는 sheet가 첫 번째가 아니라면 -names나 -n 옵션을 통해서 sheet name을 출력할 수 있습니다.
# sheet names 출력
in2csv -n(--names) SpotifyData.xlsx
# 특정 sheet를 저장
in2csv SpotifyData.xlsx --sheet "Worksheet1_Popularity" > Spotify_Popularity.csvcat, less 등의 명령어를 통해서 데이터를 확인할 수 있지만 이외에도 csvlook을 통해서 확인하는 방법을 소개합니다. csvlook은 CSV 파일을 보기에 쉽게 Markdown과 호환되는 고정 너비 형식으로 출력합니다. 위에서 csv파일로 옮겼던 파일을 실행하면 다음과 같습니다.
csvlook Spotify_Popularity.csv
마지막으로 소개할 것은 csvstat으로 Pandas 라이브러리의 describe()와 유사한 메소드입니다. csv파일의 각 열에 있는 데이터 유형을 알아서 인식하여 평균, 중앙값 및 고유 값의 개수 등과 같은 통계 정보를 출력합니다.
csvstat Spotify_Popularity.csv
2. Filtering data using csvkit
이번 강의에서는 데이터 필터링 방법에 대해 소개합니다. 데이터 파일은 테이블 형식이기 때문에 행 또는 열을 이용해서 필터링할 수 있습니다. csvcut은 열별로 데이터를 필터링할 수 있으며, csvgrep은 행별로 필터링할 수 있습니다.
csvcut은 열 이름이나 열 index를 활용해서 csv 파일을 필터링하고 자를 수 있습니다. 만약, 열 이름이나 인덱스를 모른다고 한다면 어떻게 할 수 있을까요? --names, -n을 통해서 열 이름을 확인할 수 있습니다.
# index로 접근(1열만 출력)
csvcut -c 1 Spotify_MusicAttributes.csv
# name으로 접근
csvcut -c "track_id" Spotify_MusicAttributes.csv
# 여러 column 불러오기(공백 삽입하면 안됨)
csvcut -c 2,3 Spotify_MusicAttributes.csv
# 여러 column 불러올 때, 이름으로 접근하기
csvcut -c "danceability","duration_ms" Spotify_MusicAttributes.csvcsvgrep은 행의 값으로 데이터를 필터링하기 위해 사용합니다. csvgrep은 정확하게 일치하거나 정규식 퍼지 일치로 필터링할 수 있습니다. csvgrep에는 -m(filter를 통해 얻은 row값을 추출), -r(정규표현식 패턴), -f(?) 중 하나를 사용해야 합니다. 이번 강의에서는 -m을 중점적으로 다룹니다.
만약, csv파일에서 track_id가 특정 값일 때의 row값을 가져오고 싶다면 다음과 같이 사용할 수 있습니다. -c를 통해서 track_id를 넘겨줘야 -m에 해당하는 값과 일치하는 row를 찾습니다.
# column 이름으로 접근
csvgrep -c "track_id" -m 특정값 Spotify_Popularity.csv
# column index로 접근
csvgrep -c 1 -m 특정값 Spotify_Popularity.csv3. Stacking data and chaining commands with csvkit
이번 강의에서는 여러 명령을 함께 연결하거나 한 번에 둘 이상의 파일을 처리하는 것에 대해 소개합니다. csvstack은 2개 이상의 csv 파일에서 행을 함께 쌓습니다. 동일한 스키마를 가진 파일이 있지만 API 요청 제한과 같은 다운로드 제한으로 인해 chunk로 다운로드 되었을 때 자주 사용합니다.
csvstack을 사용할 때에는 두 개의 파일이 동일한 구조의 파일이어야 합니다. 아래의 Rank6와 Rank7이 각각 2개의 행을 가진다고 했을 때, 아래와 같은 명령어로 하나의 파일로 합칠 수 있습니다.
csvstack Spotify_Rank6.csv Spotify_Rank7.csv > Spotify_AllRanks.csv두 파일은 각각 2개의 행을 포함하고 있기 때문에 csvstack을 한 뒤에는 4개의 행을 포함하는 새로운 csv파일로 변경됩니다. 하지만 이렇게 합쳤을 때, 각각의 행이 어디 파일로부터 왔는지 알 수 없습니다. 이런 경우에는 -g(group) 옵션을 통해 알려줄 수 있습니다.
csvstack -g "Rank6","Rank7" Spotify_Rank6.csv Spotify_Rank7.csv > Spotify_AllRanks.csv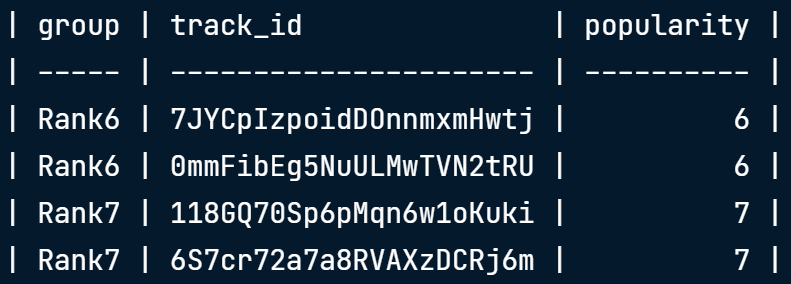
-g를 적용해줬기 때문에 group이라는 column을 통해서 각 값이 어디서부터 왔는 지 확인할 수 있습니다. 추가적으로 column 이름을 group말고 다른 것을 넣고 싶다면 -n으로 추가할 수 있습니다.
csvstack -g "Rank6","Rank7" -n "source" Spotify_Rank6.csv Spotify_Rank7.csv > Spotify_AllRanks.csv
한 번에 여러 개의 명령을 사용할 때에는 구분하기 위해 ;(세미콜론)을 활용합니다. && 연산자도 명령을 서로 연결하지만, 두 번째 명령이 실행되기 위해 반드시 첫 번째 명령이 성공해야 합니다. 또한 | 를 사용하는 경우에는 앞에서 진행한 결과를 다음 명령의 입력으로 사용합니다.