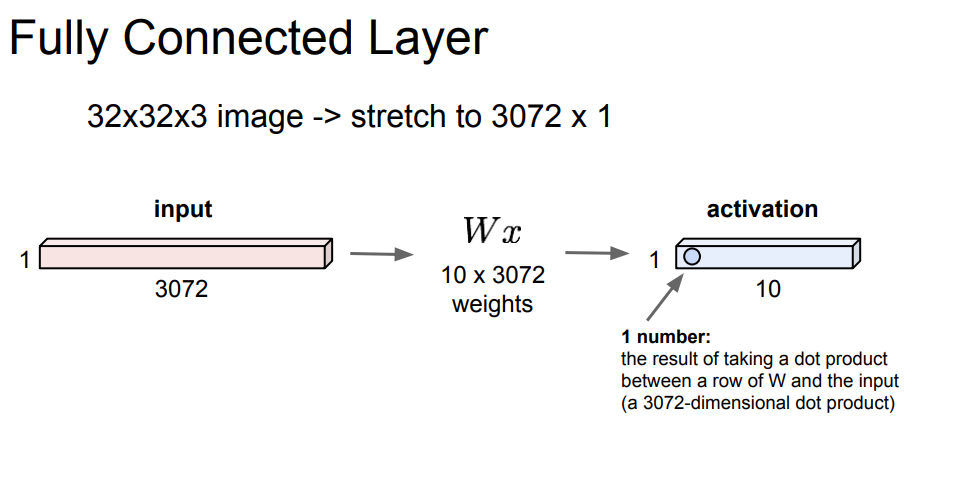
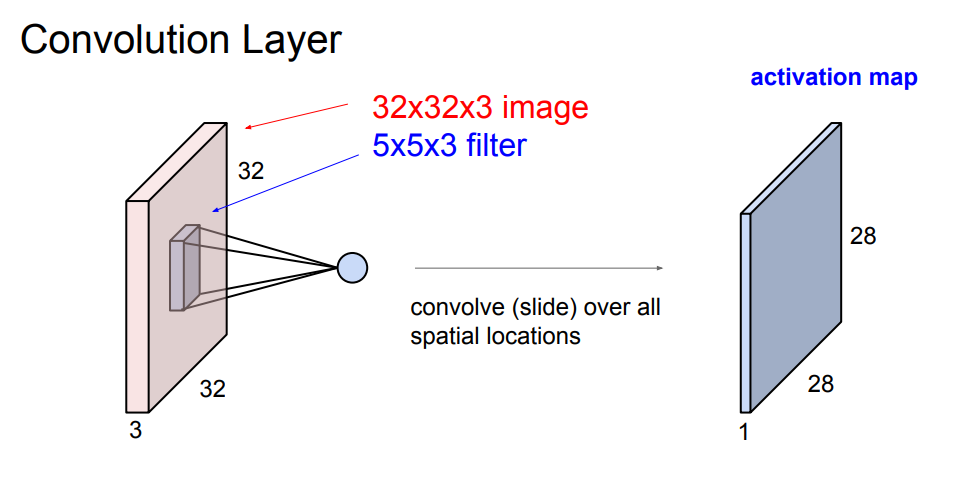
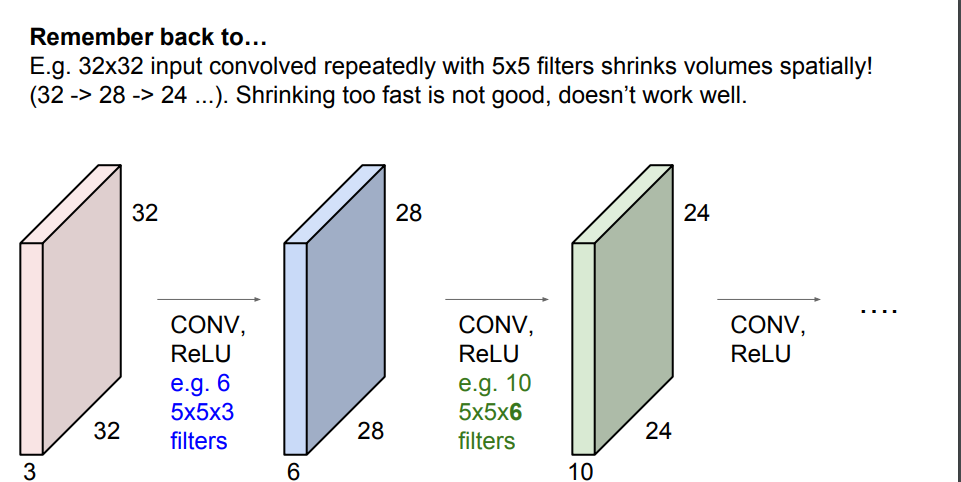
Convolution Layer와 Fully Connected Layer의 가장 큰 차이는 "이미지의 형태를 보존하는가?"라고 이해하시면 되겠습니다.
Convolution Layer
Convolution Layer
입력된 이미지에서 테두리, 선, 색 등 이미지의 특징을 감지하기 위한 층입니다.
각 이미지는 filter와의 연산(내적, dot product)으로 새로운 activation map을 생성하게 됩니다.
위의 그림에서 32X32는 이미지의 크기를 말하며, 3은 depth로 input 이미지 기준으로 RGB 값입니다. 만약, depth가 1이라면 grayscale 되어 있다고 생각하시면 되겠습니다.
이때, filter의 depth는 항상 input으로 주어진 이미지의 depth와 동일하게 설정합니다.
activation map의 크기와 개수는 stride(보폭)와 padding, filter의 값에 따라 달라집니다.
Convolution Layer 연산과정
내적 연산은 필터의 위치와 이미지의 픽셀의 위치가 같은 것끼리의 곱의 합으로 계산합니다.
위의 그림에서 초록색은 filter라고 생각하시면 됩니다.
좌측 상단부터 우측으로 slide하면서 filter와 겹치는 위치끼리 곱하고 다 더하면 3X3의 크기가 1X1 짜리의 값이 됩니다.
이때, slide하는 크기를 stride(보폭)라고 하는 데, 쉽게 말하면 몇 픽셀을 건너뛸 것인가를 정하는 부분이라고 이해하시면 되겠습니다. 만약, stride = 2이고 filter의 크기가 3X3이라고 한다면 위의 그림 상으로 7X7 input은 3X3이 될 것입니다.
그렇다면 stride = 3이고 filter의 크기가 3X3 이라면 어떤 현상이 발생할까요? 아래의 첫 번째 그림처럼 문제가 발생하게 됩니다.
input image(7X7), filter(3X3), stride(3) 이라면, Output size : (7-3)/3 +1로 계산하게 됩니다. Ouput size의 값은 2.33으로 정수 값이 되지 않습니다.
항상 Output size는 양의 정수값을 가져야 함을 잊지 않아야 합니다.
필터와 스트라이드에 따른 문제
padding
padding
padding은 위의 그림처럼 image 주변에 숫자들로 채우는 것을 말합니다.
padding은 Output size를 input size와 동일하게 하기 위한 방법으로 활용합니다.
padding의 값이 커지면 커질수록 이미지를 둘러싸는 크기는 커지게 됩니다.
보통 zero padding을 하는 것이 일반적이라고 합니다.
위의 그림의 파란색 글씨는 Filter의 크기에 따라 이미지를 보존하기 위한 pad의 크기를 표시해놓은 것입니다.
만약, padding을 사용하지 않는다면 아래와 같이 이미지 크기가 층을 layer을 지나가면서 작아지게 됩니다.
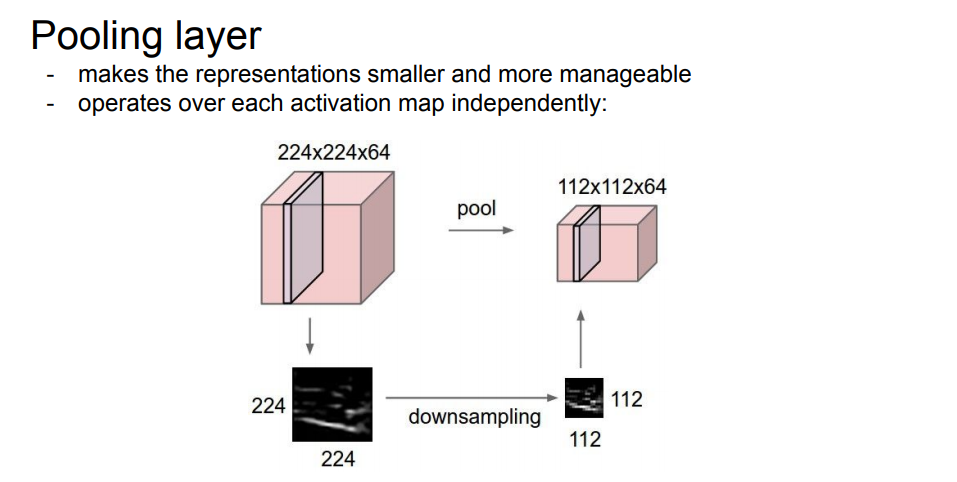
Pooling Layer
Pooling Layer
Pooling은 이미지를 다운 샘플링하기 위한 방법입니다
다운 샘플링은 쉽게 말하면 이미지 크기를 축소시키는 것이라고 생각하면 됩니다.
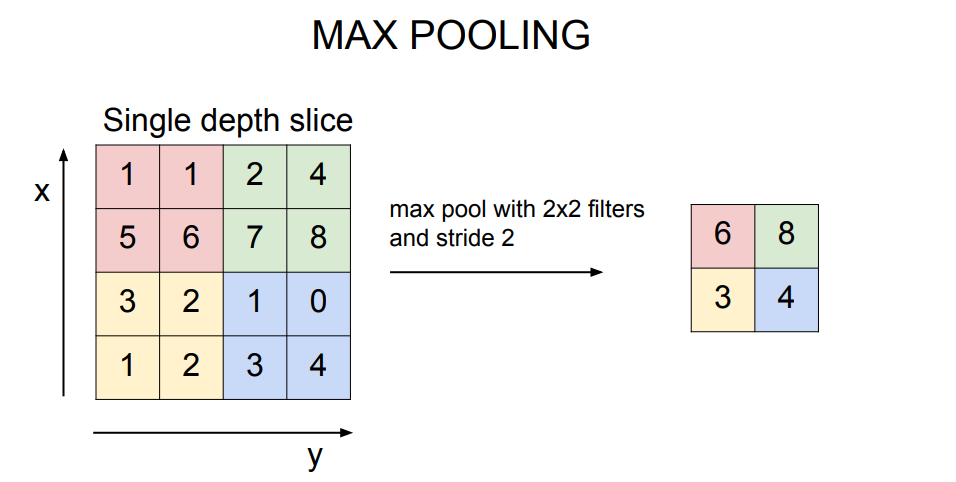
Maxpooling은 아래의 그림처럼 해당 필터 안의 최댓값을 선택하는 방법입니다. 이 외에도 평균(LeNet에서 활용)을 활용할 수도 있습니다. 하지만, 탐지된 특징을 보존하기 위해서는 maxpooling을 활용합니다.