해당 포스팅은 네이버 부스트캠프 AI Tech 학습 정리 자료임을 알려드립니다.
1. 강의 정리
오태현 교수님 - Instance/Panoptic segmentation
1) Instance segmentation

Instance segmentation은 단어에서도 느껴지듯이 Instance를 구분할 수 있는 방법입니다. 위의 그림처럼 일반 Semantic segmentation은 의자들을 구분하지 못하고 하나의 색으로 표현하고 있습니다. 반면, 우측의 Instance segmentation은 의자들을 각각 다른 색으로 표현하는 것을 확인할 수 있습니다. Instance segmentation 방법에는 Mask R-CNN, YOLACT(You Only Look At CoefficienTs), YoloactEdge 등이 있습니다.

Mask R-CNN은 이름에서부터 느껴지듯이 Faster R-CNN과 거의 동일한 구조를 가지고 있습니다. 이 모델에는 특징적인 부분은 2가지 정도가 존재합니다. 기존 모델에서는 RoI Pooling을 주로 사용했는데, 여기서는 RoIAlign이라는 방법을 사용했습니다. 두 개의 차이는 RoI pooling은 정수 픽셀 밖에 지원하지 않는다는 단점이 있습니다. 그것을 보완하는 RoIAlign은 정교한 Feature를 얻기 위해서 정교한 서브 픽셀(소수점 level) pooling을 지원합니다. 두 번째로는 Mask branch가 존재한다는 것입니다. Mask branch는 Faster R-CNN을 Object detection을 수행할 수 있도록 RoI(Region of Interest)에 Mask segmentation을 해주는 FCN(Fully Connected Network)입니다.

YOLACT(You Only Look At CoefficienTs)는 instance segmentation을 real-time으로 동작하는 모델입니다. YOLO랑 이름이 비슷하듯이 one-stage 모델입니다. YOLOACT는 one-stage object detection 모델인 RetinaNet을 수정해서 사용했고, instance segmentation task를 위해 Protonet과 Prediction Head를 병렬적으로 구성했습니다. 전체 영상에 대한 Proto-type Mask를 생성한 것이 Protonet에 해당되고, 인스턴스 당 Mask Coefficients 계수를 예측하는 것이 Prediction Head에 해당됩니다. 그래서 Prediction Head에서 나온 예측된 계수와 프로토 타입을 선형으로 결합해서 예측된 경계 상자를 크롭하는 방식으로 진행됩니다. YOLACT를 경량화한 버전인 YolactEdge도 존재합니다.
2) Panoptic segmentation
Panoptic segmentation은 instance segmentation과 다르게 배경에 관심이 있는 방법입니다. 대표적으로 UPSNet, VPSNet이 있습니다.

UPSNet은 많은 모델에서 사용한 FPN방법을 사용해서 고해상도의 Feature map을 뽑아냅니다. Semantic Head는 Fully convolution 구조로 되어 있어서 semantic map을 예측합니다. Instance Head는 물체의 detection과 box의 regression, mask의 logit을 추출합니다. 이렇게 얻어진 Head들의 결과물을 Panoptic Head를 통해서 융합해줘서 하나의 segmentation map을 만들어줍니다.

VPSNet은 Panoptic segmentation의 구조를 비디오로 확장한 방법입니다. t시점에서의 Target frame과 근처에 있는 Reference frame에서 각각의 feature map을 뽑아냅니다. Reference feature map을 Target Feature map에 align한 다음 concat해서 Spatial-temporal Attend를 학습합니다. 그렇게 reweight되어 얻어진 현재의 feature들과 reference에서 얻은 features를 Track에서 연관성을 만들어줘서 같은 물체는 같은 id를 가지도록 합니다. 이후의 과정은 앞에서의 Panoptic segementation과 크게 다르지 않습니다. VPSNet은 Image instance segmentation에 비해 동일한 instance를 tracking을 잘하는 것을 확인할 수 있습니다.
3) Landmark localization

Landmark localization은 keypoint의 위치를 추적하고 추정하는 Task입니다. 각 위치는 이미 사람들에 의해 정의해놓은 것들입니다. 대표적으로는 Hourglass network, 3차원 곡면으로 확장시킨 DensePose, RetinaFace이 존재합니다.
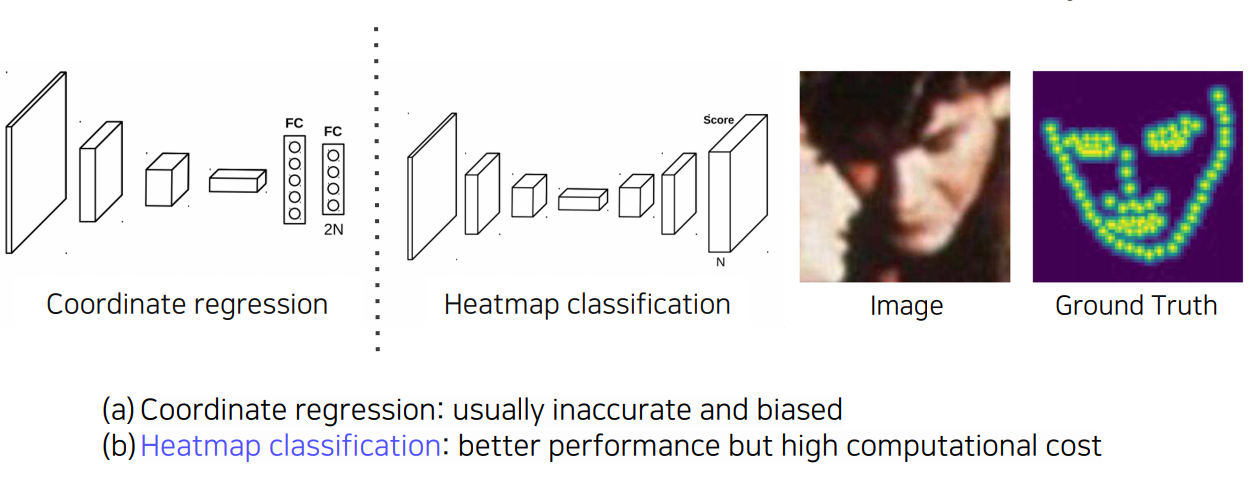
key point를 찾는 방법에는 Coordinate regression과 Heatmap classification이 있습니다. Coordinate regression은 x, y 좌표를 예측하는데, 부정확하고 일반화되지 않는 문제가 있습니다. Heatmap classification은 채널들이 각 키포인트를 담당하는 방식입니다. Coordinate regression보다 좋은 성능을 가지지만 모든 픽셀에 대해서 해야하기 때문에 비용이 많다는 단점이 존재합니다.

Landmark location을 heatmap 형태로 변환하기 위해서는 아래와 같은 수식으로 변환할 수 있습니다.
$$ G_{\sigma}(x, y) = exp(- \frac{(x-x_{c})^2 + (y-y_{c})^2}{2\sigma^{2}}), (x_{c}, y_{c}) = center \, location $$
4) Detecting objects as keypoints
보통 Object detection할 때, bounding box로 4개의 지점을 포함하고 있지만, CornerNet과 CenterNet에서는 다른 방법을 사용해서 bounding box를 뽑아냈습니다. CornerNet에서는 Top-Left, Bottom-right 2개의 점으로 표현하는 방법입니다. CenterNet에서는 Top-left, Bottom-right, Center 3개의 점으로 표현하는 방법입니다. 또 다른 CenterNet에서는 Width, Height, Center로 표현합니다. 이러한 방법을 활용하게 되면, 기존의 bounding box보다 속도가 빨라지게 됩니다.
오태현 교수님 - Conditional Generative Model
1) Conditional generative model
Conditional generative model은 주어진 정보(조건)에 의해 나오는 결과를 확률 분포로 표현할 수 있습니다. 이렇게 얻어진 확률 분포를 샘플링해서 새로운 샘플을 생성하는 모델입니다. Generative model의 경우에는 랜덤으로 생성되서 우리가 조작해줄 수 없었습니다. 반면, Conditional generative model은 조건을 통해서 우리가 원하는 형태의 이미지를 생성할 수 있도록 할 수 있는 특징이 있습니다. 이러한 생성 모델은 vision 분야 외에도 다양한 분야에서 활용됩니다. 저 해상도의 오디오를 고해상도의 오디오로 높여주는 것도 conditional generative model이라고 볼 수 있습니다. 또한 자연어처리 분야에서도 기계어 번역이 conditional generative model에 해당됩니다. 이외에도 article generation도 있습니다.

위의 그림은 Generative Adversarial Network가 어떻게 학습하는 지를 보여주고 있습니다. Generator는 Fake data를 만들고, 실제 데이터와 Fake data를 생성해서 Discriminator를 속이는 것을 목표로 합니다. 반면, Discriminator는 Fake data가 진짜인지 가짜인지 맞추도록 합니다. 이러한 과정을 반복하면서, Generator는 Discriminator를 속이기 위해 학습하고, Discriminator는 Fake 데이터를 구별하기 위해 계속 학습하게 됩니다.

위의 그림은 대표적으로 GAN을 활용한 image to image translation 방법입니다. 이외에도 동영상의 테마를 바꾸는 Style Transfer, 저해상도 그림을 고해상도로 변경해주는 Super resolution도 존재합니다.

Super resolution방법은 condition으로 Low resolution image를 넣어줍니다. Generator는 이 이미지를 통해 Fake HR image를 생성하게 됩니다. 생성된 이미지와 진짜 이미지의 차이인 loss를 계산하게 됩니다.

이때, 픽셀 단위로 비교하는 MAE, MSE를 사용하게 되면, 모든 주어진 이미지들의 평균으로 생성하게 됩니다. 파란색이 MSE loss로 생성한 이미지입니다. 우리가 GAN을 통해서 다른 patch들 중 구분하기 어려운 patch를 만드는 것이 목표이기 때문에 노란색의 patch를 만드는 것이 더 좋은 방법입니다. 예를 들어, 실제 이미지에 흰색의 이미지와 검은색 이미지들만 있었다고 가정해봅시다. L1 loss를 사용하게 된다면, 회색의 이미지를 생성하게 될 것입니다. 우리는 흰색이나 검은색 이미지를 생성해야 하기 때문에 GAN loss를 사용하는 것이 더 적절합니다.

위의 그림에서 볼 수 있듯이 GAN loss를 사용한 SRGAN이 original image와 매우 유사한 것을 확인할 수 있습니다.
2) Image translation GAN

Image translation은 한 이미지 스타일을 다른 스타일의 이미지로 변환하는 Task입니다. CNN 구조를 이용해서 학습기반으로 처음 정리한 연구가 Pix2Pix라는 방법입니다.
Pix2Pix에서는 loss function으로 L1 loss를 사용하게 되면, 블러 처리가 된 이미지들을 생성하게 된다는 것을 말하고 있습니다. 그래도 적당한 가이드로 활용하기에는 좋을 수 있다고 판단했습니다. 그래서 Pix2Pix에서는 아래와 같은 loss function을 제시했습니다.
$$ G^* = arg \underset{G}{min} \underset{D}{max} \mathcal{L}_{cGAN}(G,D) + \lambda \mathcal{L}_{L1}(G)$$
$$\mathcal{L}_{cGAN}(G, D) = \mathbb{E}_{x, y} [log D(x, y)] + \mathbb{E}_{x, z} [log(1 - D(x, G(x,z))], \, \mathcal{L}_{L1}(G) = \mathbb{E}_{x, y, z} [||y - G(x, z)||_{1}] $$
여기서 $\mathcal{L}_{cGAN}(G, D)$는 x, y를 독립적으로 비교합니다. 그래서 만들어진 결과가 y와 같은 결과를 만들어낼 수 없습니다. 반면, $\mathcal{L}_{L1}(G)$는 y와 직접 비교하기 때문에 추가해줘서 y와 비슷하게 만들도록 하는 효과를 얻을 수 있습니다. 또한 MAE loss는 GAN 방법에 비해 비교적 안정적으로 학습이 진행되기 때문에, 불안정한 GAN을 보완해주는 역할을 합니다.

위의 그림을 보시면, L1 loss를 사용한 것은 다른 이미지에 비해 흐릿한 것을 확인하실 수 있습니다. cGAN의 경우 Ground truth에서의 이미지를 일부 반영하지 못하는 것을 확인할 수 있습니다. L1 + cGAN을 사용해서 생성한 이미지는 Ground Truth와 가장 비슷하고 현실적인 이미지를 생성하는 것을 확인할 수 있습니다.
Pix2Pix의 경우 supervised-learning이기 때문에 쌍으로 얻어진 데이터(1:1 대응)가 필요합니다. paired data를 사용하기 어려운 경우가 많이 있습니다. CycleGAN방법은 Unpaired 데이터들을 활용해서 paired data를 구하기 어려울 때 사용하는 방법입니다.

CycleGAN은 non-pairwise datasets을 활용해서 서로 다른 도메인의 이미지를 변환하도록 학습하는 방법입니다. 이렇게 했을 때, 활용할 수 있는 범위가 늘어나는 장점이 있습니다. CycleGAN의 loss는 GAN loss(양방향)와 Cycle-consistency loss를 더해서 사용합니다.
$$ L_{GAN}(X \rightarrow Y) + L_{GAN}(Y \rightarrow X) + L_{cycle}(G, F), \, where \, G/F \, are \, generators $$
X 도메인에서 Y 도메인으로 변환하는 것과 Y 도메인에서 X 도메인으로 변환하는 것을 동시에 학습을 진행합니다. Cycle-consistency loss는 X 도메인의 A 이미지를 변환해서 B 이미지를 얻습니다. 그런 다음에 B 이미지를 X 도메인으로 보내서 얻어진 A'를 기존 이미지 A와 비교해서 같은 지를 확인합니다. 만약 GAN loss만 사용하게 되면, Mode Collapse라는 문제가 발생하게 됩니다. 여기서의 Mode Collapse는 input에 관계 없이, Generator가 항상 똑같은 output을 만드는 것을 말합니다. 그래서 이러한 문제를 해결하기 위해서 Cycle-consistency loss를 활용합니다.
하지만, GAN은 학습하기가 굉장히 어렵습니다. Discriminator와 Generator를 반복적으로 학습을 시켜야 하기 때문입니다. 그렇다면 우리는 어떻게 GAN을 사용하지 않고도 좋은 이미지를 얻을 수 있을까요? 그런 방법이 Perceptual loss로 구현이 가능합니다.
Perceptual loss는 비교적 간단한 forward & backward computation으로 구성되어 있어서 training하는 것이 쉽습니다. 대신 loss를 측정하기 위해 pre-trained network를 사용해야 합니다. Perceptual loss는 content(원본)이 잘 유지하기 위한 Feature reconstruction loss와 Style을 배우기 위한 Style reconstruction loss로 구성되어 있습니다. 만약, super resolution처럼 style 변경이 필요없는 task의 경우에는 Feature reconstruction loss만 사용하기도 합니다.
3) Various GAN applications

GAN의 대표적인 응용사례는 Deepfake를 가장 먼저 떠올릴 수 있을 것입니다. 존재하지 않은 사람의 얼굴만 생성하는 것이 아니라, fake연설을 생성할 수도 있습니다. 그렇게 했을 때, 사회에 엄청난 어려움을 가져올 것이라고 생각합니다. 그래서 이것을 막기 위해서 다양한 연구들이 진행되고 있습니다.

위의 사례는 privacy를 보호하고자 만들어진 방법으로, 사람의 얼굴을 변화시켜서 다른 사람처럼 보이도록 변경하는 것이라고 생각하시면 될 것 같습니다.

password를 잘못넣었을 때, 이상한 얼굴이 나오도록 하는 방법입니다. 이를 통해 얼굴을 익명화해서 프라이버시를 보존하는 방법입니다. 또한 이외에도 video에 적용하는 Pose transfer, video-to-video translation, video-to-game 등과 같은 것들도 있습니다.