해당 포스팅은 네이버 부스트캠프 AI Tech 학습 정리 자료임을 알려드립니다.
1. 강의 정리
주재걸 교수님 - Sequence to Sequence with Attention
1) Sequence to Sequence
Sequence to Sequence의 형태는 어제 강의에서도 설명했듯이 RNN의 many to many에 해당됩니다. 예를 들어, 영어로 된 문장인 "I love soccer"가 input으로 들어오게 되면, input이 끝나는 지점부터 "나는 축구를 사랑한다."를 출력하는 방법입니다. 이 모델은 Encoder와 Decoder로 구성되어 있는 데, Encoder는 입력 문장을 읽어내는 RNN 모델이며, Decoder는 입력된 문장을 통해 출력 문장을 순차적으로 한개씩 생성하는 RNN 모델입니다. 기본적으로 여기서 <SOS>, <EOS>라는 스페셜 토큰이 존재하는 데, 이것들은 각각 문장의 시작, 끝을 알려주는 토큰입니다. 그래서 decoder에서 시작할 때, <SOS>로 시작하며 <EOS>로 끝나게 됩니다. 기존의 RNN 모델에서는 모든 파라미터가 동일했지만, 여기서에서는 인코더와 디코더가 다른 파라미터를 가집니다.
인코더를 통해서 학습된 문장을 hidden state에 저장해서 마지막으로 저장된 hidden state를 decoder의 0번째 hidden state로 입력하는 방식으로 정보가 전달됩니다. 하지만 이렇게 진행된다면, 마지막 hidden state에 모든 입력 단어들의 정보가 들어가야 하기 때문에 소실되거나 변질될 수 있다는 단점이 있습니다. 이것을 해결하기 위해서 입력을 역순으로 넣어주기도 했고, 이를 해결하는 attention 방법이 있습니다.
2) attention
attention 방법은 디코더에서 각 인코더 time step에서 발생한 hidden state들의 유사도를 측정해서 이를 분포로 만들어서 선택합니다. 가장 기본적인 dot product를 활용한 attention 모델의 모습을 아래에 표현했습니다.
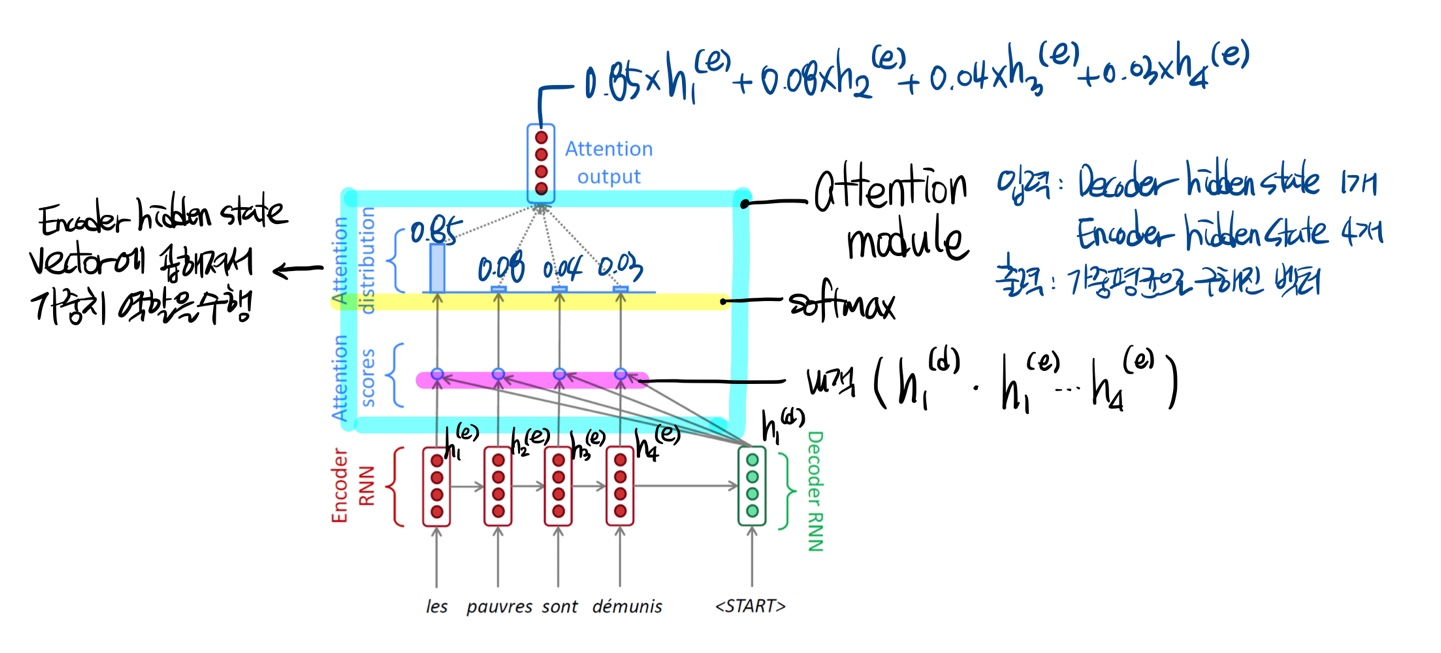
Encoder RNN 부분에서 각각의 time step의 hidden state vector를 가지고 있다가, Decoder RNN을 통해 얻은 hidden state vector와 내적을 통해서 attention score를 구해줍니다. 구해진 attention score를 softmax로 attention 분포를 만들고, 해당 분포로 얻어진 값(attention vector)을 각 time step의 hidden state vector들과 곱해서 합해준 가중평균 벡터를 output으로 얻을 수 있습니다.

이렇게 얻어진 output vector와 Decoder의 hidden state vector와 concatenate를 통해서 다음 나올 예측값을 구하는 방식으로 진행됩니다. 이러한 모델을 초기에 학습시킬 때에는 ground truth 값을 넣어주는 teacher forcing 방법을 적용하면 빠르게 학습을 할 수 있습니다. 왜냐하면 처음에 예측을 잘못하면 그 예측 값이 다음 스텝에 영향을 주게 되는 현상이 발생하기 때문입니다. 그래서 잘못된 예측을 해도 바로잡아 줄 수 있도록 실제 값을 다음 스텝에 넣어줘서 올바르게 학습하도록 도와줍니다. 하지만 인퍼런스할 때에는 실제 환경과 차이가 발생하게 됩니다. 그래서 이를 보완하기 위해 처음에는 Teacher forcing으로 학습하다가 어느정도 학습이 되었다면 예측값을 넣어주는 방식을 사용하기도 합니다. 위에서는 dot product를 통해서 두 벡터의 유사도를 구하는 방법을 사용했습니다. 이 외에도 다양한 방법이 존재합니다.
$$ dot : h_{t}^{T} \bar{h_{s}}, \, general : h_{t}^{T}W_{a}\bar{h_{s}}, \, concat : v_{a}^{T}tanh(W_{a}[h_{t};\bar{h_{s}}])$$
general은 벡터와 벡터 내적 사이에 가중치를 포함할 수 있는 행렬을 추가하고 이 행렬을 학습할 수 있는 방법입니다. 또한 concat은 두 벡터를 concat해서 $W_{a}$를 통해 벡터형태로 얻은 값을 tanh함수를 거친 뒤 $v_{a}^{T}$와 곱해서 스칼라 값을 얻도록 하는 방법입니다.
attention은 기계어 번역 성능을 훌륭하게 향상시켰으며, 긴 문장을 한 벡터에 모든 담아서 소실될 수 있는 현상을 극복할 수 있었습니다. 또한 vanishing gradient 문제를 해결할 수 있었습니다.
주재걸 교수님 - Beam Search and BLEU
1) Beam Search
Beam Search는 Sequence to Sequence with attention 자연어 생성 모델에서 Test time에서 보다 좋은 품질의 생성 결과를 얻을 수 있도록 하는 기법입니다. Beam Search 기법을 설명하기 이전에 Greedy decoding, Exhaustive search를 설명하려고 합니다.
먼저, Greedy decoding 방법은 가장 높은 확률을 가지는 단어 하나를 통해 Decoding하는 방법으로 현재 타임 스텝에서 가장 좋아보이는 것을 선택하는 방법입니다. 하지만 가장 좋은 것을 선택했지만 잘못 예측했을 때 이를 바꿀 수 없는 문제가 발생합니다.
Exhaustive search는 디코더에서 출력된 모든 단어를 고려하는 방법입니다. 기본 아이디어는 아래와 같은 수식과 같습니다.
$$ P(x|y) = P(y_{1}|x) P(y_{2}|y_{1}, x) ... P(y_{T}|y_{1},...,y_{T-1}, x) = \prod_{t=1}^{T}P(y_{t}|y_{1}, ... , y_{t-1}, x)$$
이 방법은 연산의 수가 너무 많아서 현실적으로 어렵습니다. 그래서 이 두가지를 결합해서 만들어 낸 방법이 Beam search 입니다.
Beam Search 방법은 가장 확률이 높은 k개의 경우의 수(hypothesis)만 고려하는 것입니다. 주로 k의 사이즈는 5~10을 주로 사용합니다.
$$ score(y_{1}, ... , y_{t}) = logP_{LM}(y_{1},...,y_{t} | x) = \sum_{i=1}^{t}logP_{LM}(y_{i} | y_{1}, ... , y_{i-1}, x)$$
여기서 $P_{LM}$은 항상 0과 1사이의 값이기 때문에 log를 취하게 되면 항상 음수가 나오게 됩니다. 그래서 값이 클 수록 좋습니다. 우리는 각 스텝마다 가장 높은 k개의 값을 고르게 됩니다. 하지만, 이 방법은 global 최적 해를 찾는 것을 보장하지는 않습니다. 그렇지만 exhaustive search 방법에 비해 더 효과적이기 때문에 사용합니다. 아래는 Beam size = 2라고 했을 때, 찾아가는 과정을 표현한 그림입니다.

위의 그림처럼 노란색 형광색으로 칠해져 있는 부분이 해당 step에서 가장 값이 큰 2개의 값을 표현한 것입니다. 그래서 선택받지 못한 부분에서는 가지처럼 뻗어나가지 못하는 것을 볼 수 있습니다. 이 방법에서는 서로 다른 시점에서 END 토큰이 발생하게 됩니다. 그렇기 때문에 END 토큰이 나온 문장을 임시로 저장하고 있고 계속 찾아가는 과정을 진행합니다. 이 방법이 멈추기 위해서는 2가지 조건 중 하나를 만족하면 되는데, 하나는 우리가 설정한 time step T에 도달하면 종료하도록 합니다. 다른 하나는 end 토큰이 나온 가설이 n개가 모이면 종료하는 방법입니다. 이렇게 모여진 가설 중에서 가장 높은 하나의 score를 선택합니다. 하지만, 위의 표에서도 알 수 있듯이 문장의 길이가 짧으면 짧을수록 값이 작습니다. 그렇다면 무조건 짧은 문장이 유리한 문제가 발생할 것입니다. 그래서 이를 보정해주기 위해서 Normalize하는 방법으로 각 문장의 길이로 score를 나눠주는 방법을 사용합니다.
2) BLEU
BLEU는 자연어 생성모델에서 생성 모델의 품질이나 결과의 정확도를 평가하는 척도입니다. 항상 어떤 모델을 만들게 되면 그에 맞는 평가하는 척도를 적용해야 합니다.

위에 그림처럼 Predicted는 우리가 학습한 모델로 예측한 값입니다. 언뜻보면 굉장히 우리가 예측해야 하는 값과 비슷한 것을 볼 수 있습니다. 여기서는 confusion matrix에서 나오는 개념인 precision과 재현율을 이용해서 측정한 결과가 위와 같습니다. 여기서 정밀도는 예측된 결과가 노출되었을 때, 사람들이 실질적으로 느끼는 모델의 정확도를 말합니다. 재현율은 얼마나 빠짐없이 정보를 노출시켜줬는 지를 알 수 있는 지표입니다. 맨 마지막에 F-measure의 경우는 정밀도와 재현율을 조화평균을 해줘서 얻은 값이 되는 데, 여기서 조화평균은 산술평균보다 낮은 값에 가중치를 많이 주는 방법입니다. 이러한 지표들을 모델의 성능을 확인할 때 사용하면 어떻게 될까요?

이 예에서 볼 수 있듯이 Model 2는 순서가 뒤죽박죽으로 되어 있지만, 위에서 언급한 Precision, Recall, F-measure값이 다 100%로 나오는 것을 볼 수 있습니다. 이처럼 순서에 대한 패널티가 존재하지 않기 때문에 사용할 수 없습니다. 그래서 BELU score를 활용해서 성능평가를 하게 됩니다.
여기서 N-gram이라는 개념이 추가되는데, N-gram은 N개의 단어와 동일한 것이 정답에 포함되어 있는지를 확인하는 것입니다. n-gram은 보통 1~4까지의 값을 사용해서 precision을 사용하게 되는데 precision을 사용하는 이유는 모델이 얼마나 빠짐없이 번역을 했는가가 중요한 것이 아니고 얼마나 맞췄는지가 중요하기 때문입니다. 이를 통해 얻어진 식은 아래와 같습니다.
$$ BLEU = min(1, \frac{length-of-prediction}{length-of-reference})(\prod_{i=1}^{4}precision_{i})^{\frac{1}{4}}$$
앞에 최소값에 해당되는 항을 brevity penalty라고 하는 데 이것은 짧은 문장에 대해 penalty를 부여하는 항이라고 보면 됩니다. 우리가 예측한 것이 정답보다 짧다면 1보다 작은 값이 곱해질 것이고, 1보다 크다면 1이 곱해지는 방식으로 됩니다. 이 항을 통해서 Recall을 고려하고 있습니다. 뒤의 항은 precision값에 대한 기하평균으로 곱해준 것을 볼 수 있습니다. 여기서 조화평균을 사용하지 않은 이유는 기하평균보다 더 낮은 값에 가중치를 많이 주기 때문입니다.

BLEU 방법을 통해서 계산하게 되면 위와 같은 결과를 얻을 수 있습니다. 이를 통해서 Model 1이 성능이 더 좋다는 것을 알 수 있게 됩니다.
2. 피어 세션 정리
질문
-
further question : BLEU는 어떠한 단점이 존재할까요?
-
BLEU는 짧은 문장에 과하게 패널티를 주는 것 같습니다.
-
-
BLEU는 왜 4-gram까지만 사용할까요?
-
실질적으로 어절과 어절의 거리가 멀어지면 의미 상 관계성이 사라지기 때문입니다.
-