해당 포스팅은 네이버 부스트캠프 AI Tech 학습 정리 자료임을 알려드립니다.
1. 강의 정리
주재걸 교수님 - Transformer 1
1) Transformer
Transformer는 자연어를 입력으로 받아서 다른 자연어를 출력하는 LSTM이나 GRU와 같이 Sequence to Sequence 모델의 성능을 개선한 모델입니다. Transformer는 기존의 Sequence 데이터 입력과 출력을 처리할 때 사용하는 RNN 모델을 대신해서 attention으로 처리합니다. RNN 기반의 모델의 경우 Long-Term Dependecy가 발생하기 때문에 이를 해결하고자 attention이라는 기법을 사용하게 됩니다.

오늘 소개할 것은 attention을 활용해서 Encoder hidden state vector를 구하는 과정입니다. 여기서 발생하는 연산은 행렬곱에 의해서 동시에 진행되지만, 이해를 돕기 위해 Day 18의 attention 구조와 비교하면 쉬울 것 같습니다. 위의 attention 구조에서는 각 타임스텝에 따라 encoder hidden state vector와 decoder hidden state vector를 내적해서 구한 값을 softmax를 거쳐서 attention 분포를 구하고 Encoder hidden state vector와 곱해서 가중평균을 구했습니다. 이와 비슷한 방식으로 진행됩니다.

각 input이 Embedding된 벡터 $x_{1}, x_{2}, x_{3}$가 존재하는데, 이 벡터를 각 각 query, key, value 벡터로 변경하는 $W$를 곱합니다. 그리고나서, 변경된 query와 각 input에 대한 key 벡터를 내적해서 두 벡터사이의 유사도를 구합니다. 유사도 구한 벡터를 softmax로 가중치로 변경해서 각 가중치를 해당되는 value 벡터에 곱한 다음 더해주는 가중평균을 구해서 우리가 원하는 encoder hidden state를 구할 수 있습니다. query 벡터가 $x_{1}$에 해당되는 값을 사용했다면, 결과로 나온 값은 $h_{1}$이 됩니다.
여기서, query와 key는 서로 내적을 해야하기 때문에 동일한 벡터 차원을 가져야 하지만 value는 꼭 같은 dimension이 아니여도 괜찮습니다. 곧바로 내적을 해주는 방법은 단어의 길이가 길어질수록 분산이 커지는 현상이 발생합니다. 이렇게 분산이 커지게 되면, softmax 함수의 특성 상 큰 값에 많은 가중치를 주는 문제가 발생하기 때문에 이를 보완하기 위해서 Scaled Dot-Product라는 방법으로 $QK^{T}$(query와 key의 내적)를 $\sqrt{d_{k}}$ 값으로 나눠주면 분산을 조정해줄 수 있습니다.
주재걸 교수님 - Transformer 2
1) Multi-Head Attention
Multi-Head Attention은 self attention을 유연하게 확장한 방법입니다.

위의 그림처럼 앞에서 배운 attention module을 동일한 query, key, value에 대해 병렬적으로 여러가지의 버전의 attention을 수행합니다. 각각의 attention은 다 다른 weight값을 가집니다. 이렇게 나온 인코딩 벡터들은 모두 head라고 부르며 이 head를 모두 concatenate한 것을 MultiHead라고 부르게 되며 아래와 같이 표현됩니다.
$$ MultiHead(Q, K, V) = Concat(head_{1}, ... , head_{h})W^{0}, where \, head_{i} = Attention(QW_{i}^{Q},KW_{i}^{K}, VW_{i}^{V})$$
우리는 동일한 시퀀스 정보가 주어졌을 때, 동일한 query word에 대해서 여러가지 다양한 측면의 데이터를 필요로 할 수 있습니다. 이럴 경우 하나의 attention으로는 모든 정보를 담을 수 없기 때문에 각각의 Head에 다른 정보들을 저장함으로써 하나의 단어에 여러가지 정보를 포함할 수 있게 됩니다. 그렇게 각기 다른 Weight를 통해서 계산된 Head들은 아래와 같은 그림으로 concatenate됩니다.

열의 개수는 value vector의 크기와 attention의 개수를 곱한 값이 되며, 행의 개수는 input으로 들어간 query 단어와 같습니다. $W^{0}$는 concat된 행렬을 원하는 차원으로 만들어 줄 수 있는 linear layer에 해당됩니다.
2) RNN과 Self attention의 성능 차이

위의 그림처럼 층 마다의 시간복잡도를 구해보면 위의 그림처럼 계산해볼 수 있습니다. self-attention의 경우, Query 벡터들이 $d$라는 차원을 가지면서 $n$개가 존재하고, Key 벡터들도 동일합니다. 이를 전치해준 것을 곱해줄 때, 총 d번의 연산으로 한 칸이 계산되며, 총 그러한 계산이 $n^{2}$만큼 필요하게 되어 위와 같은 값이 나오게 됩니다. RNN의 경우에는 이전 스테이트에서 다음 스테이트로 넘어갈 때 필요한 weight는 $d$ 차원의 정방행렬이 되고, hidden state vector는 $d$ 차원을 가지는 벡터입니다. 그림처럼 행렬곱을 하게 되면 총 $d^{2}$의 경우의 수를 얻게 됩니다. 추가적으로 $n$ 이란 time step을 곱해준 값이 됩니다.
여기서 $d$의 경우 임의로 정할 수 있는 하이퍼파라미터이지만 $n$은 우리가 정해줄 수 없는 가변적인 파라미터입니다. 그렇기 때문에 self-attention이 더 많은 용량을 차지하게 됩니다. 하지만, 실행 측면에서는 충분한 GPU 자원이 보장이 된다면 GPU에 특화된 행렬연산으로 인해 self-attention은 한 번에 계산이 가능합니다. 하지만, RNN은 이전 time step의 정보가 넘어올 때까지 기다려야 하기 때문에 더 느린 특징을 가지고 있습니다. 마지막으로 Maximum Path Length는 Long Term Dependency와 관련이 있습니다. 예를 들면, RNN의 경우에는 맨처음의 단어가 마지막 단어에 영향을 주기까지 걸리는 시간은 최대 $n$시간이 걸리지만, self-attention은 한번에 모든 값에 접근이 가능합니다.
3) Block-Based Model

위의 그림은 Block-Based Model의 encoder 부분입니다. 위의 그림처럼 input이 들어오게 되면, 그 벡터는 Value, Key, Query를 생성하고 앞서 말했던 Multi-Head Attention 과정을 통해 최종 벡터를 얻게 됩니다. 얻게된 벡터는 처음에 들어간 벡터와 Residual Connection을 통해 더해집니다. 그 후 Layer Normalization을 진행하게 됩니다. Feed Forward는 Normalization된 벡터를 fully connected layer를 지나가게 해서 각 단어의 인코딩 벡터로 변환합니다. 보통 Feed Forward에는 2개의 linear transformation과 1개의 ReLU로 이뤄져 있습니다. 이렇게 나온 값을 앞에서 했던 것과 동일한 더하기 연산과 Normalization을 통해 1블럭의 Encoder를 수행하게 됩니다.
4) Layer Normalization

Normalization은 일반적으로 주어진 다수의 샘플들에 대해서 그 값들의 평균을 0, 분산을 1로 만들어준 후 우리가 원하는 평균과 분산을 주입할 수 있도록 하는 선형변환으로 이뤄집니다.
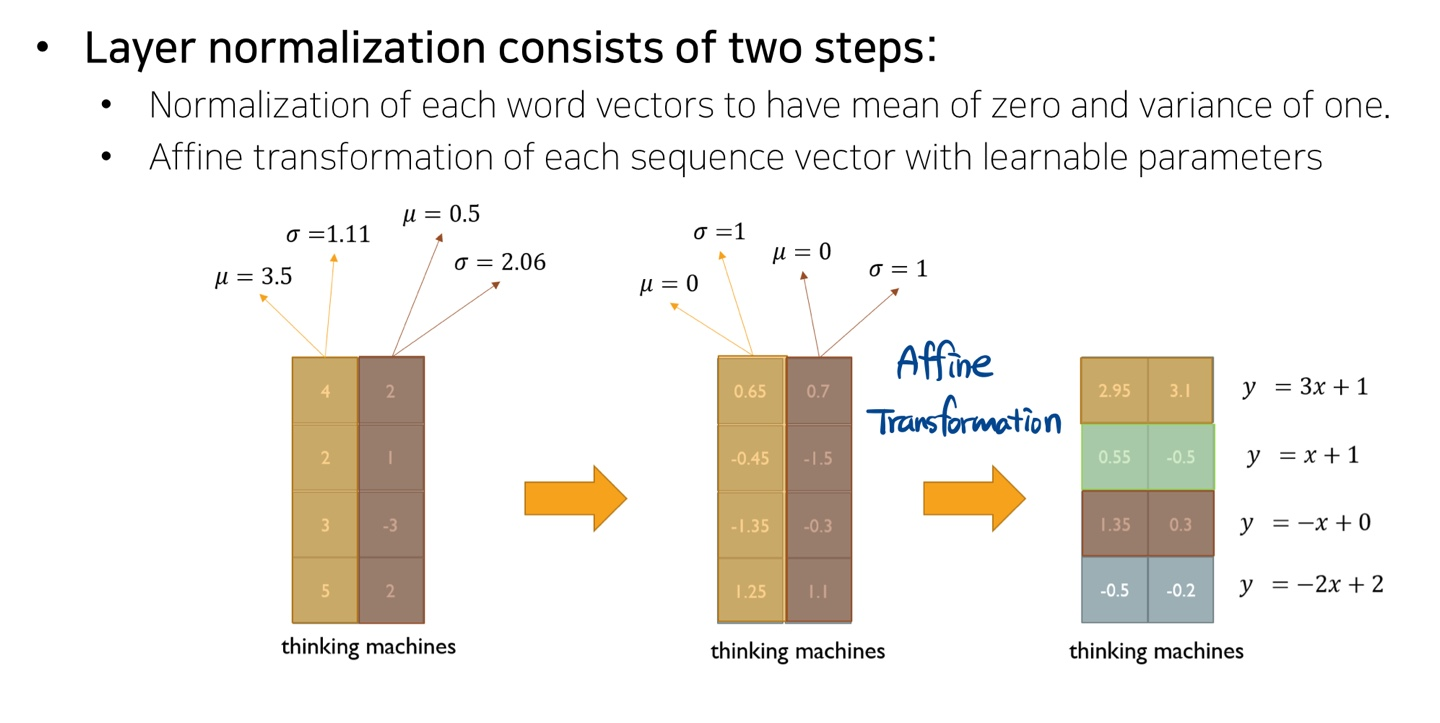
Encoder에서 현재 사용하고 있는 normalization 방식은 위의 그림과 같습니다. (여기서 말하는 affine transformation으로 각 함수는 어떻게 구하는 것인가..?? 찾아봐야겠습니다.)
5) Positional Encoding
attention의 경우는 시간 정보가 포함되어 있지 않아 순서가 바뀌어도 동일한 값을 가지게 됩니다. 이러한 시간 정보를 보강해주기 위한 방법이 Positional Encoding입니다.

이처럼 sin과 cos을 주기를 다르게 해서 주어진 벡터에 더해주면서 unique한 특성을 가지는 벡터로 만들어 줄 수 있습니다. 우측 하단의 그림처럼 행의 값들을 해당 벡터에 더해주는 방법입니다.
6) Warm-up Learning Rate Scheduler

Learning rate는 항상 학습에서 1순위로 중요한 하이퍼파라미터입니다. transformer에서는 위와 같은 방법인 Warm-up Learning Rate Scheduler를 사용하는데, 중간에 갑자기 learning rate가 높아지는 부분은 local minima에 빠지는 것을 막기 위한 방법으로 사용됩니다. 이러한 방법을 통해서 시간 흐름에 따라 learning rate를 변화시켜서 최적 해에 도달할 수 있도록 해줍니다.
7) high-level view
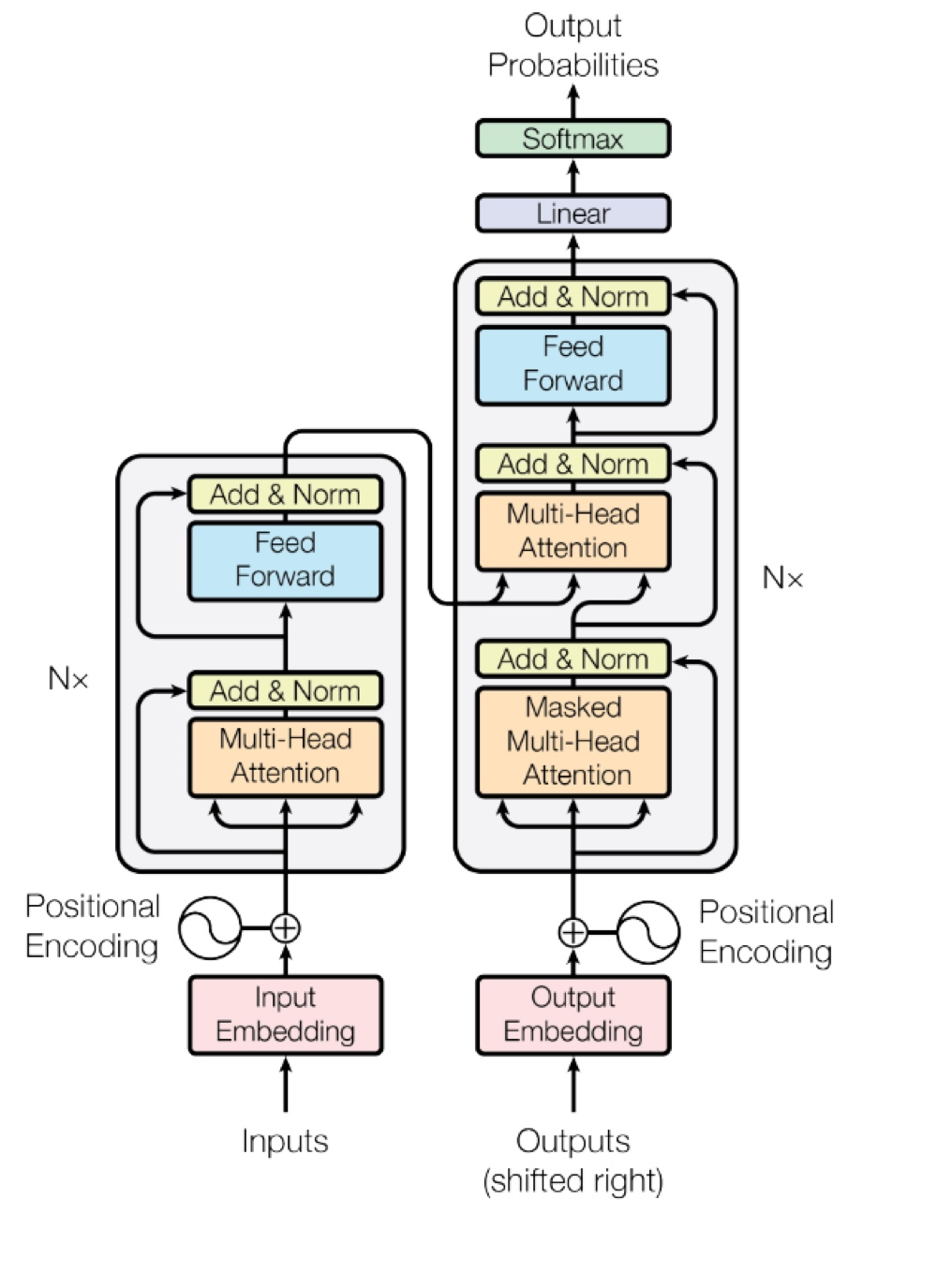
지금까지 Encoder에 있는 모든 내용들을 다뤘습니다. block으로 이뤄진 Encoder를 N개로 쌓아서 나온 Output은 추후 Decoder의 Multi-Head Attention의 Key, Value로 들어가게 되어, Decoder에서 만들어진 Query 벡터와의 유사도를 측정하는 방식으로 진행됩니다. 여기서 마지막으로 Masked-Multi-Head Attention에 대해 알아보겠습니다.
8) Masked Multi-Head Attention
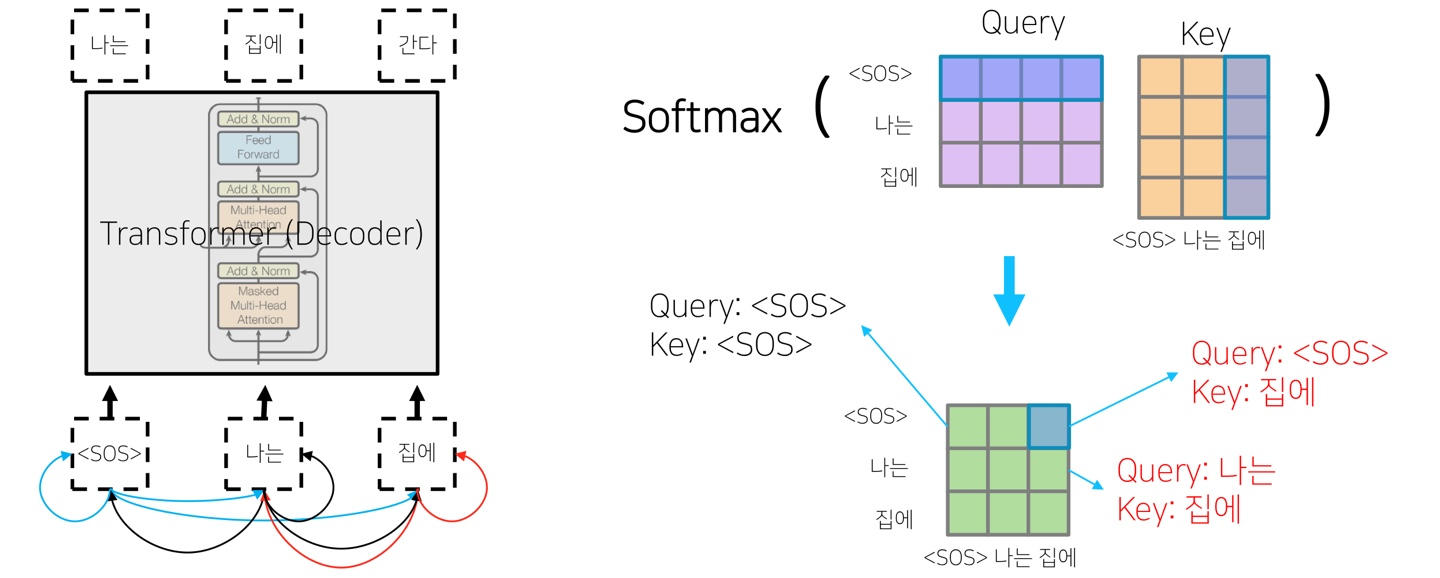
위의 그림처럼 주어진 단어를 주고 다음 단어를 예측하는 그림에서 각 정보에 접근 가능여부와 관련있는 것이 Masked Self-Attention입니다. 우측의 그림은 각 단어 벡터를 활용해서 self attention을 하게 된 모습입니다. 초록색으로 만들어진 것은 각 Query 벡터와 Key 벡터와의 유사도를 가지고 있는 행렬이 됩니다. 예측과정을 생각해보면 <SOS>가 들어왔을 때에는 "나는"과 "집에"는 input으로 들어오지 않은 상태입니다. 그래서 이러한 접근을 막도록 도와주는 방법이 Masked Self-Attention입니다.
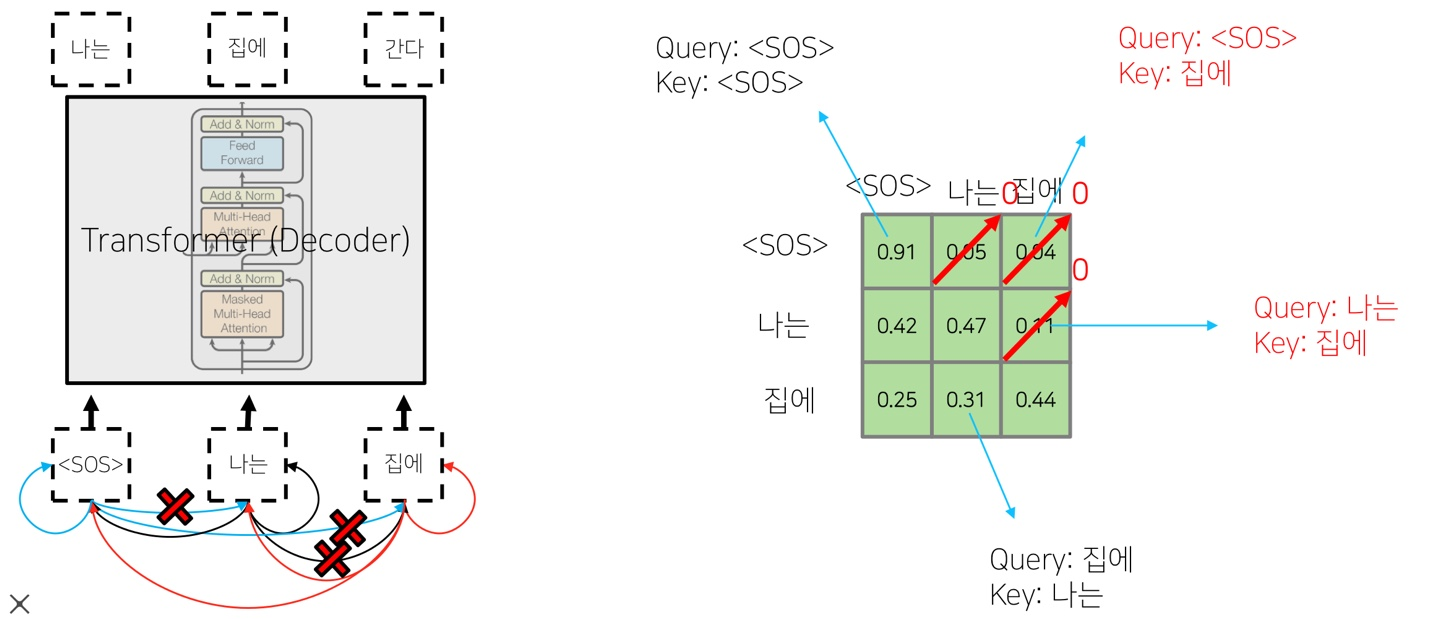
위의 그림처럼 <SOS>가 나왔을 때, "나는"과 "집에"에 접근하지 못하도록 0으로 바꿔주게 됩니다. 그래서 얻어진 행렬의 상삼각행렬의 값을 0으로 바꿔주게 되고, 나머지 값들은 행별로 확률이 1이 되도록 조정해주는 과정을 거치게 됩니다. 이러한 과정을 넣어줌으로 인퍼런스 환경과 비슷하게 만들어주는 효과를 얻을 수 있습니다.
2. 피어 세션 정리
질문
-
어제 수업 attention에서 인코더를 가지고 첫번째 디코더와 concatenate 연산 이후 어떤 과정이 있는가?
-
코드를 확인해보니 실제로 linear함수를 거치게 됩니다.
-
inference는 softmax가 반드시 있어야 합니다.
-
-
multi-head attention 한 문장에 대해서 단어별로 다양한 weight를 가지고 key, value를 만들어냄
-
한 단어에 대해서 다양한 측면으로 분석하기 위함
-
-
lr scheduler는 어떤 것이 좋을까??