해당 포스팅은 네이버 부스트캠프 AI Tech 학습 정리 자료임을 알려드립니다.
1. 강의 정리
주재걸 교수님 - Recurrent Neural Network and Language Modeling
1) RNN

RNN은 기본적으로 위의 그림과 같은 구조를 가지고 있습니다. 특징으로는 각 타임 스텝에 따른 입력값이 순서가 있는 데이터로 들어가며, 중간에 있는 A라는 모듈은 어떤 타임 스텝에서도 동일한 구조로 이루어져 있습니다. 이러한 과정을 통해 h값을 얻어서 다음에 나올 단어를 예측할 수 있습니다.

위의 그림에서는 RNN의 기본적인 원리에 대해서 설명하고 있습니다. 보시는 것처럼 RNN은 모든 time step에서 재귀식/점화식(recurrence formula)을 적용해서 작동하게 됩니다. 점화식(recurrence formula)은 이웃하는 두개의 항 사이에 성립하는 관계를 나타낸 식을 말합니다.
위의 식에 적용해보면 $h_{t}$에 대한 점화식이라고 볼 수 있습니다. RNN은 t시점의 새로운 상태인 $h_{t}$는 old state인 $h_{t−1}$와 t시점의 input vector인 $x_{t}$로 구할 수 있습니다. 여기서 특징적인 것은 모든 RNN에서는 동일한 function과 파라미터 W를 사용해야 한다는 것입니다.

Vanilla RNN에서는 위에서 보시는 것처럼 tanh함수를 사용했습니다. tanh함수는 비선형성을 위해 적용하게 되었는데, 선형함수를 사용하게 되면, 층을 거치면서 크게 변화가 발생하지 않습니다. tanh함수는 RNN의 gradient가 최대한 오래 유지할 수 있도록 해주는 역할로 사용됩니다. 여기서 사용된 $W_{hh}$는 h와 h 사이의 파라미터, $W_{xh}$는 x에서 h 사이의 파라미터, $W_{hy}$는 h에서 y 사이의 파라미터로 사용됩니다. 여기서는 tanh함수를 사용했는데, Binary classification을 할 대, output vector는 1차원이 되고, 이 때 sigmoid를 활용해서 확률값을 예측값으로 계산할 수 있습니다. 비슷한 맥락으로 Multi classification의 경우 클래스 개수만큼의 차원을 가지게 되고, softmax를 통해 클래스와 동일한 확률분포를 얻을 수 있습니다.
2) RNN의 종류

첫 번째, one to one은 입력과 출력이 1개인 것으로 대표적으로 Vanilla Neural Network가 있습니다. Vanilla Neural Network는 가장 기본적인 네트워크를 말합니다. 여기서 Vanilla는 바닐라향을 쓴 아이스크림으로 가장 흔하고 아이스크림의 기본이라 할 수 있을 정도로 '표준'이라는 느낌을 줍니다. 그래서 Vanilla라는 단어를 사용한 것 같습니다. 예시로는 키, 몸무게, 나이와 같은 3차원 입력이 들어갔을 때, 저혈압인지, 고혈압인지, 정상인지를 고르는 경우를 들 수 있습니다. 이 경우에는 time step으로 이뤄져 있지 않습니다.
두 번째, one to many는 입력은 1개, 출력은 여러 개인 방법으로 대표적인 예로 이미지 캡셔닝(image captioning)이 있습니다. 이미지 캡셔닝은 이미지를 단어로 설명하는 기술을 말합니다. 이때, input으로는 이미지가 들어가며, 이미지 내부의 물체들에 대해 여러 개의 단어로 변환하여 설명하게 되기에 one to many의 한 예라고 볼 수 있습니다. 여기서 비어있는 input자리에는 사이즈가 동일한 영벡터로 입력을 넣어 줍니다.
세 번째, many to one은 입력은 여러 개, 출력은 하나인 방법입니다. 예를 들면, "나는 오늘 육개장을 먹어서 행복하다."라는 문장을 input을 받아서 output으로 "행복"과 같은 감정을 출력하는 감정 분류(setiment Classification)이 대표적인 방법입니다.
네 번째, many to many는 두 가지로 나눠지는 데, 전자의 대표적인 것은 번역(Machine Translation)이 있습니다. 나라마다 언어의 길이나 크기가 다르기 때문에 입력의 크기와 출력의 크기가 다를 수 있습니다. 입력이 모두 들어온 다음부터 단어를 하나씩 번역해서 출력값을 얻어냅니다. 후자의 경우 비디오 분류(Video classification)나 PoS tagging을 예로 들 수 있습니다.
3) Character-level Language Model

위의 그림은 "hello"라는 sequence data를 주고, 정답을 찾을 수 있는 지 확인하는 예시입니다. 여기서 저희가 사용할 알파벳은 4개이므로, 4개를 각각 원-핫 인코딩을 통해 벡터화해서 Vocabulary에 저장했습니다. 그리고 input으로는 "h"를 넣었을 때에는 "e"가 출력되고, "e"를 입력으로 넣었을 때에는 "l"이 출력되도록 만듭니다. 이러한 방법으로 학습하게 되는 데 "h"를 넣었을 때 "e"값이 출력되는 확률이 높아지도록 학습을 진행하게 됩니다. 위의 예시는 Vanilla RNN이므로 tanh함수를 활용했습니다. 최종 결과 쪽을 보시면, 이상한 것을 알 수 있습니다. "e"는 [0,1,0,0]이지만, output layer에서는 [1, 2.2, -3, 4.1]로 4.1이 가장 큰 값인 것을 확인할 수 있습니다. 하지만, 가장 큰 값을 출력하는 것이 아닌 샘플링을 통해서 값을 출력하게 됩니다. 때로는 argmax가 좋을 때가 있지만, 샘플링을 통해 모델에서 다양성을 얻을 수 있다는 장점이 있습니다. 예를 들면, "e"가 나오면 무조건 "l"이 아닐 수도 있습니다. 이처럼, 다양성을 위해 샘플링으로 최종 값을 출력합니다.
4) Backpropagation through time (BPTT)

전체 시퀀스가 길어지거나 계산량이 많아지면 그레디언트를 한꺼번에 계산하기가 어렵습니다. 메모리 측면에서 전체 시퀀스 대신 일부를 잘라내서 forward와 backward를 병행하면서 학습을 진행합니다.
RNN은 훌륭하지만 gradient가 vanishing 되거나 exploding하는 현상이 발생하게 됩니다. 그 이유는 forward 과정에서 h에 대한 값에 $W_{hh}$값이 계속 곱해지는 현상때문입니다. 만약 이 값이 1보다 크다면, exploding현상을 1보다 작다면 vanishing되는 결과를 얻게 됩니다. 그래서 이를 보완하는 방법인 LSTM이 등장하게 되었습니다.
주재걸 교수님 - LSTM and GRU
1) LSTM
LSTM은 cell state 정보를 다른 변형없이 지나갈 수 있도록 만든 방법입니다. 이러한 방법으로 인해 타임 스텝이 멀어도 정보 전달이 잘 되기 때문에 학습이 잘 됩니다.

여기서 $C_{t}$는 완성된 정보를 포함하는 것이며, $h_{t}$는 filtering된 정보를 담는 차이가 있습니다. 위의 그림처럼 LSTM에는 총 4개의 게이트가 존재합니다.
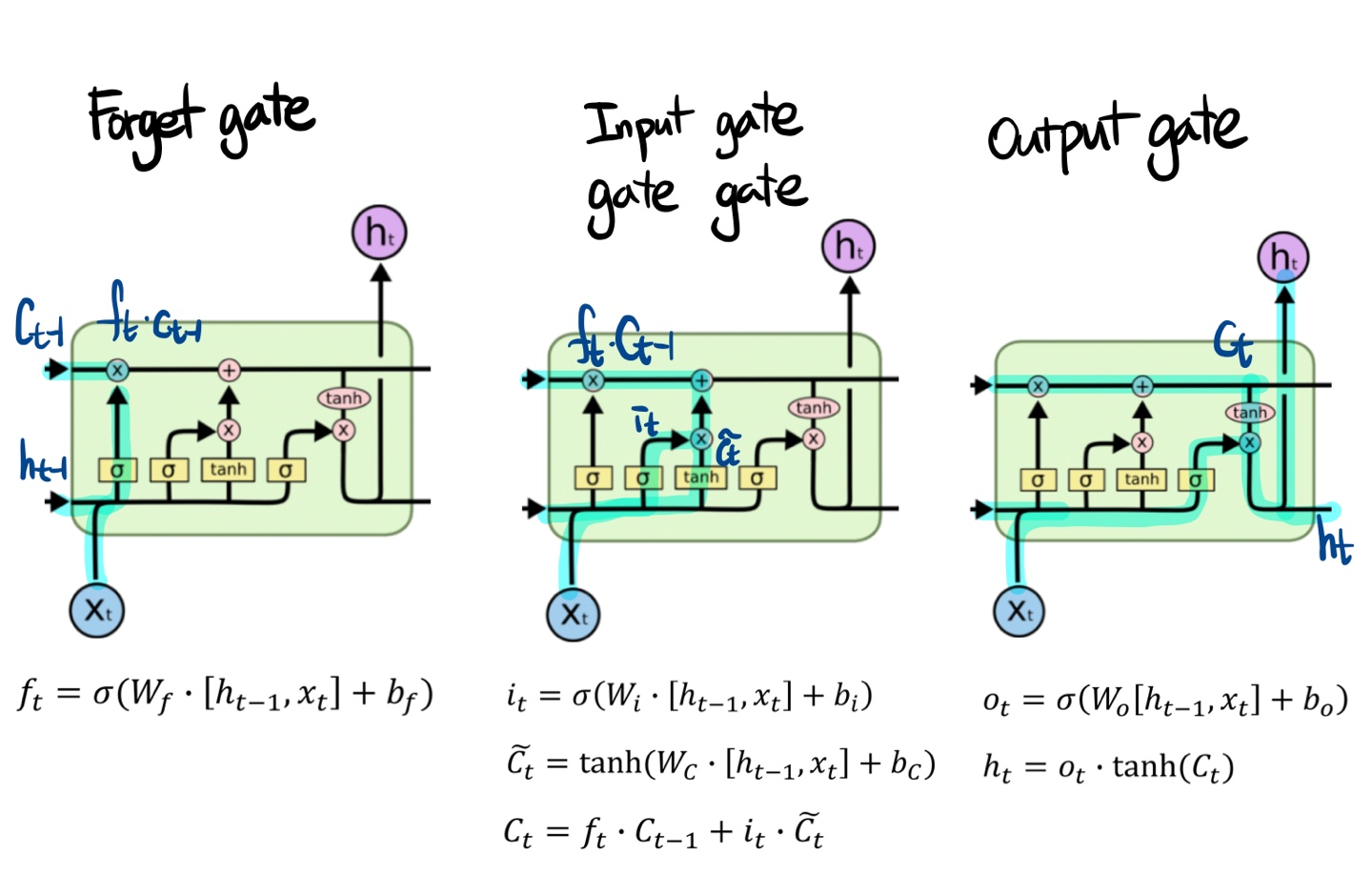
먼저 좌측에 있는 forget gate는 이전의 정보를 얼만큼 버릴 것인지에 대한 gate입니다. 그렇게 나온 결과를 이전의 cell state값과 곱해지게 됩니다. 여기 위에 $\widetilde{C_{t}}$는 gate gate이며, input을 얼마나 포함시킬 것인지에 대한 게이트입니다. 그 옆으로 sigmoid로 나온 값은 input gate입니다. 이렇게 두개가 곱해진 값이 forget gate 연산 이후에 나온 값과 더해지게 됩니다. 그렇게 나온 값이 t시점에서의 cell state가 됩니다. 이렇게 더해지는 연산은 RNN의 vanishing gradient나 exploding gradient 현상을 막는 역할을 합니다. 마지막으로, Output gate는 cell state가 tanh를 지나고 output gate에서 나온 값과 곱해지면서 t시점의 hidden state가 되며, 이 state는 결과 값에 영향을 주게 됩니다. 이 $h_{t}$에는 현재 타임 스텝에서 예측값을 내기 위해 output에 들어가는 정보와 예측에 직접적으로 필요한 데이터만 포함하고 있습니다.
2) GRU

GRU는 LSTM과 유사하지만 다른 점은 LSTM에서 가지고 있던 cell state와 hidden state를 하나의 hidden state에서 관리합니다. 또한 t시점에서의 hidden state를 구할 때, forget gate 대신 1-input gate 값을 활용해서 가중평균 값을 구합니다.
2. 피어 세션 정리
질문
-
자연어 처리에서 Word2Vec에서 Vector는 어떻게 표현할 수 있는가?
-
먼저 Word2Vec에서 학습이 충분히 되었다면, 각 단어를 나타내는 벡터는 $W_{1}$, $W_{2}$ 어떤 것을 사용해도 상관없습니다.
-
-
RNN에서 인퍼런스할 때 출력 값은 어떻게 뽑아올 수 있는가?
-
cs231n에서는 softmax를 확률분포로 보고 임의로 추출하는 형태로 뽑아내는 형태입니다. 가장 naive한 방법은 softmax output에 argmax 연산을 해서 가장 높은 확률 값을 갖는 character를 넘겨줄 수 있습니다. 이 외에도 다양한 decoding strategy를 사용할 수 있는 데, 50%에 해당되는 후보군에서만 sampling하거나 후보 character가 100개인 경우 확률값 기준 상위 5개의 character 중에서만 sampling하는 방법도 존재합니다.
-
-
GloVe 목적함수에 대하여
-
임베딩 벡터 간의 내적의 의미?
-
내적은 전체 말뭉치의 동시등장확률
-
-
log는 왜 발생하는가?
-
$w_{i}$와 $w_{k}$가 바뀌어도 식이 같은 값을 반환해야합니다.
-
$X$는 대칭행렬이므로, $X^{T}$와 같아야 합니다.
-
homomorphism 조건을 만족해야 합니다.
-
위의 조건을 만족하는 것이 지수함수입니다.
-
-
참고자료 : ratsgo.github.io/from%20frequency%20to%20semantics/2017/04/09/glove/
-